搜狗网站做滤芯怎么样百度登录页面
基于朴素贝叶斯分类器的钞票真伪识别模型
内容
本实验通过实现钞票真伪判别案例来展开学习朴素贝叶斯分类器的原理及应用。
本实验的主要技能点:
1、 朴素贝叶斯分类器模型的构建
2、 模型的评估与预测
3、 分类概率的输出
源码下载
环境
- 操作系统:Windows10、Ubuntu18.04
- 工具软件:Anaconda3 2019、Python3.7
- 硬件环境:无特殊要求
- 核心库:
-
numpy 1.19.4
-
ipython 7.16.2
-
scikit-learn 0.24.2
-
pandas 1.1.5
-
mglearn 0.1.9
-
原理
1、数据集
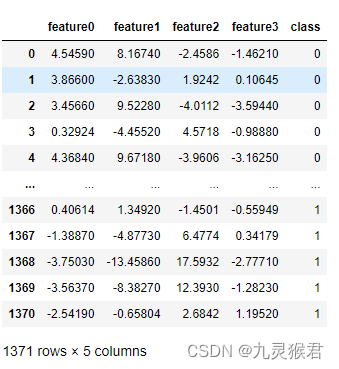
钞票数据集包括1371行、5列,前四列是钞票的四个光学图像指标(即样本的特征),最后一列是钞票的真伪(0-真币,1-假币,即样本的标签)。因为训练数据是有标签的,因此本实验是监督学习中的一个分类问题。
本任务涉及以下几个环节:
a)加载、查看数据集
b)获取样本的特征数组和标签数组
d)将数据集拆分为训练集和测试集
e)构建模型拟合数据、评估并做出预测
2、分割测训练集和测试集
sklearn.model_selection.train_test_split(train_data,train_target,test_size=0.25, random_state=0)
在机器学习中,我们通常将原始数据按照比例分割为“测试集”和“训练集”,从 sklearn.model_selection 中调用train_test_split 函数 ,参数列表如下
- train_data:被划分的样本特征集
- train_target:被划分的样本标签
- test_size:如果是浮点数,在0-1之间,表示样本占比;如果是整数的话就是样本的数量
- random_state:是随机数的种子
- 若为None时,每次生成的数据都是随机,可能不一样
- 若为整数时,每次生成的数据都相同
步骤
打开notebook 开发环境,新建ipynb文件,命名为实验一:基于朴素贝叶斯分类器的钞票真伪识别模型.ipynb保存在当前项目根目录下的code文件夹中。
步骤一 加载、查看数据集
我们使用pandas读取数据集文件,增加列名。
from sklearn.naive_bayes import GaussianNB # 引入高斯朴素贝叶斯分类器
from sklearn.model_selection import train_test_split # 数据集拆分
from IPython.display import display # 显示import pandas as pd
import numpy as np# 读取钞票数据文件
banknote = pd.read_csv('../dataset/banknote.csv')# 添加列名
banknote.columns=['feature0', 'feature1','feature2','feature3','class']# 显示数据框
display(banknote)显示结果:
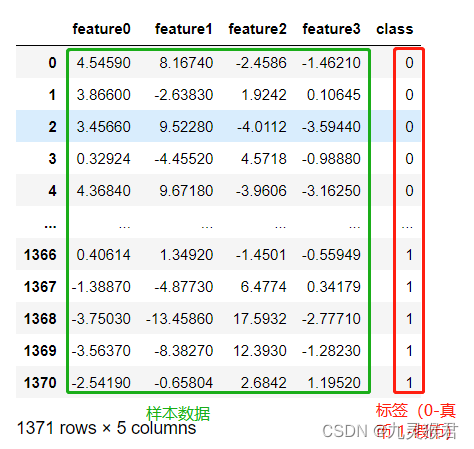
钞票的四个特征分别对应其光学图像检测参数:
-
feature0-小波变换图像指标
-
feature1-小波偏斜变换图像指标
-
feature2-小波峰度变换图像指标
-
feature3-图像熵
共1371条数据,4个特征列,1个标签列。
步骤二 将数据集拆分为训练集和测试集
# 获得样本特征数组data(前4列)
data = banknote.values[:,0:4]# 获得样本标签数组target(最后一列)
target = banknote.values[:,-1]print(data.shape) # 查看样本特征数组形状
print(target.shape) # 查看样本标签数组形状# 数据集拆分,辅助函数可以很快地将实验数据集划分为任何训练集(training sets)和测试集(test sets)。
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.25, random_state=0)print(X_train.shape, X_test.shape) # 查看拆分结果显示结果:
(1371, 4)
(1371,)
(1028, 4) (343, 4)
步骤三 创建模型,评估并预测
# 创建贝叶斯分类器
model = GaussianNB().fit(X_train, y_train) # 训练# 输出模型在训练集和测试集上的准确率
train_score = model.score(X_train, y_train) # 得分
test_score = model.score(X_test, y_test)
print(train_score, test_score)# 在测试集上预测钞票真伪
num = 10 # 显示的样本数量
y_pred = model.predict(X_test) # 预测
print('y_pred:', y_pred[:num]) # 预测结果
print('y_true:', y_test[:num]) # 实际结果
y_proba = model.predict_proba(X_test[:num]) # 预测结果的概率(每个样本为真钞和假钞的概率)
print(np.around(y_proba, decimals=3))输出结果:
0.8424124513618677 0.8542274052478134
# 预测结果(0-真币,1-假币)
y_pred: [0. 0. 1. 0. 0. 0. 0. 0. 1. 1.]
y_true: [1. 0. 1. 0. 0. 0. 0. 0. 1. 1.]
# 预测结果个概率
[[0.588 0.412][0.998 0.002][0. 1. ][0.998 0.002][0.998 0.002][0.953 0.047][0.681 0.319][0.994 0.006][0. 1. ][0.054 0.946]]
贝叶斯分类器除可以输出预测结果外,还可以输出样本属于每个类别的可能性概率,可以通过predict_proba方法来输出。