茂名网站优化百度引擎搜索
1.HDFS简介
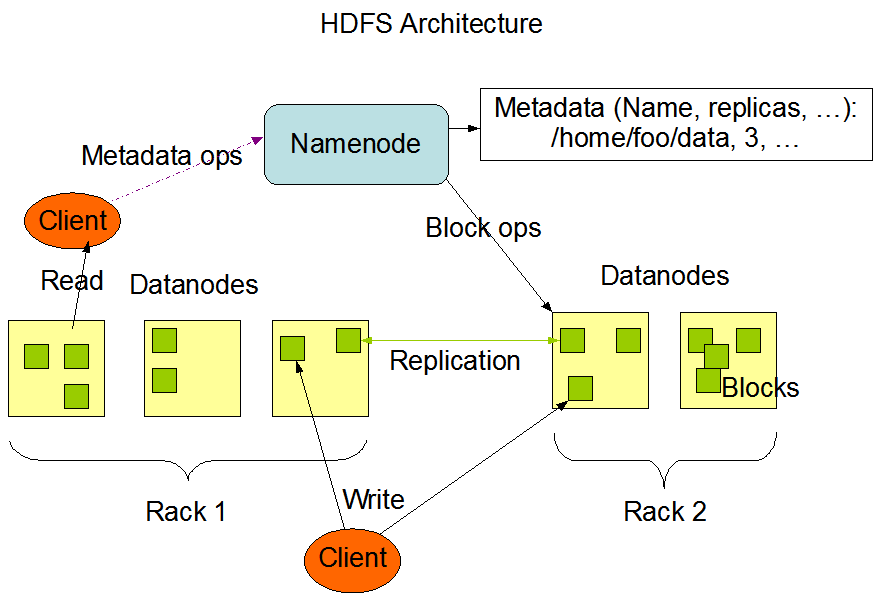
| 2.1 Hadoop分布式文件系统-HDFS架构
|
| 2.2 HDFS组成角色及其功能 (1)Client:客户端 (2)NameNode (NN):元数据节点 管理文件系统的Namespace元数据 一个HDFS集群只有一个Active的NN (3)DataNode (DN):数据节点 数据存储节点,保存和检索Block 一个集群可以有多个数据节点 (4)Secondary NameNode (SNN):从元数据节点 合并NameNode的edit logs到fsimage文件中 辅助NN将内存中元数据信息持久化 |
| 2.3 HDFS副本机制 (1)Block:数据块 HDFS最基本的存储单元,默认块大小:128M(2.x) (2)副本机制 作用:避免数据丢失 副本数默认为3 存放机制:一个在本地机架节点;一个在同一个机架不同节点;一个在不同机架的节点 |
| 2.4 HDFS优缺点 (1)HDFS优点:高容错性;适合大数据处理;流式数据访问;可构建在廉价的机器上 (2)HDFS缺点:不适合低延时数据访问场景;不适合小文件存取场景;不适合并发写入,文件随机修改场景 |
2.HDFS基本文件操作命令
| 2.1 准备工作 1)启动单机Hadoop 2)-help:输出这个命令参数 hdfs dfs -help rm 3)创建/install文件夹 hdfs dfs -mkdir /sanguo |
| 2.2 上传 1)-moveFromLocal:从本地剪切粘贴到HDFS 2)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去 3)-put:等同于copyFromLocal,生产环境更习惯用put
4)-appendToFile:追加一个文件到已经存在的文件末尾 |
| 2.3 HDFS直接操作 1)-ls: 显示目录信息 hadoop fs -ls /sanguo 2)-cat:显示文件内容 hadoop fs -cat /install/shuguo.txt 3)-chgrp、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限 hadoop fs -chmod 666 /sanguo/shuguo.txt hadoop fs -chown atguigu:atguigu /sanguo/shuguo.txt 4)-mkdir:创建路径 hadoop fs -mkdir /jinguo 5)-cp:从HDFS的一个路径拷贝到HDFS的另一个路径 hadoop fs -cp /sanguo/shuguo.txt /jinguo 6)-mv:在HDFS目录中移动文件 hadoop fs -mv /sanguo/wuguo.txt /jinguo hadoop fs -mv /sanguo/weiguo.txt /jinguo 7)-tail:显示一个文件的末尾1kb的数据 hadoop fs -tail /jinguo/shuguo.txt 8)-rm:删除文件或文件夹 hadoop fs -rm /sanguo/shuguo.txt
9)-rm -r:递归删除目录及目录里面内容 hadoop fs -rm -r /sanguo
10)-du统计文件夹的大小信息 hadoop fs -du -s -h /jinguo 27 81 /jinguo hadoop fs -du -h /jinguo 14 42 /jinguo/shuguo.txt 7 21 /jinguo/weiguo.txt 6 18 /jinguo/wuguo.tx 说明:27表示文件大小;81表示27*3个副本;/jinguo表示查看的目录 11)-setrep:设置HDFS中文件的副本数量(集群) hadoop fs -setrep 10 /jinguo/shuguo.txt
这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。 |
| 2.4 进入资源管理器web页面:http://kb129:8088 |
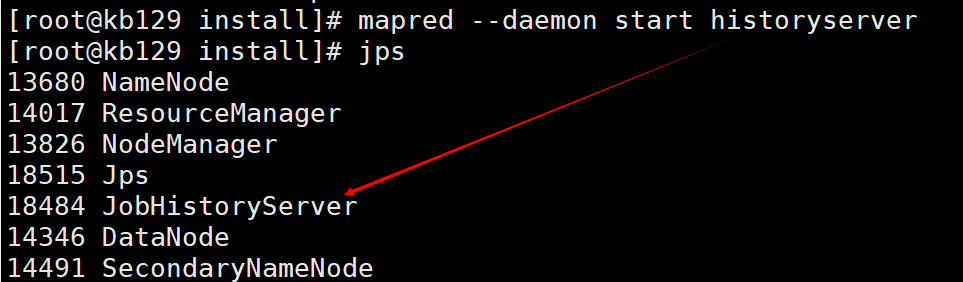
| 2.5 查看历史服务器 (1)启动历史服务器:mapred --daemon start historyserver
(2)进入历史服务器网页访问:http://kb129:19888 |



3. windows中hadoop环境搭建
| 3.1 解压hadoop313至C盘server目录下,配置环境变量HADOOP_HOME C:\server\hadoop313 将winutils.exe放至C:\server\hadoop-3.1.3\bin目录下 将hadoop.dll放至C:\Windows\System32目录下
|
4. Java实现HDFS文件读写
| 4.1 创建maven工程,quickstart工程 (1)配置依赖
|
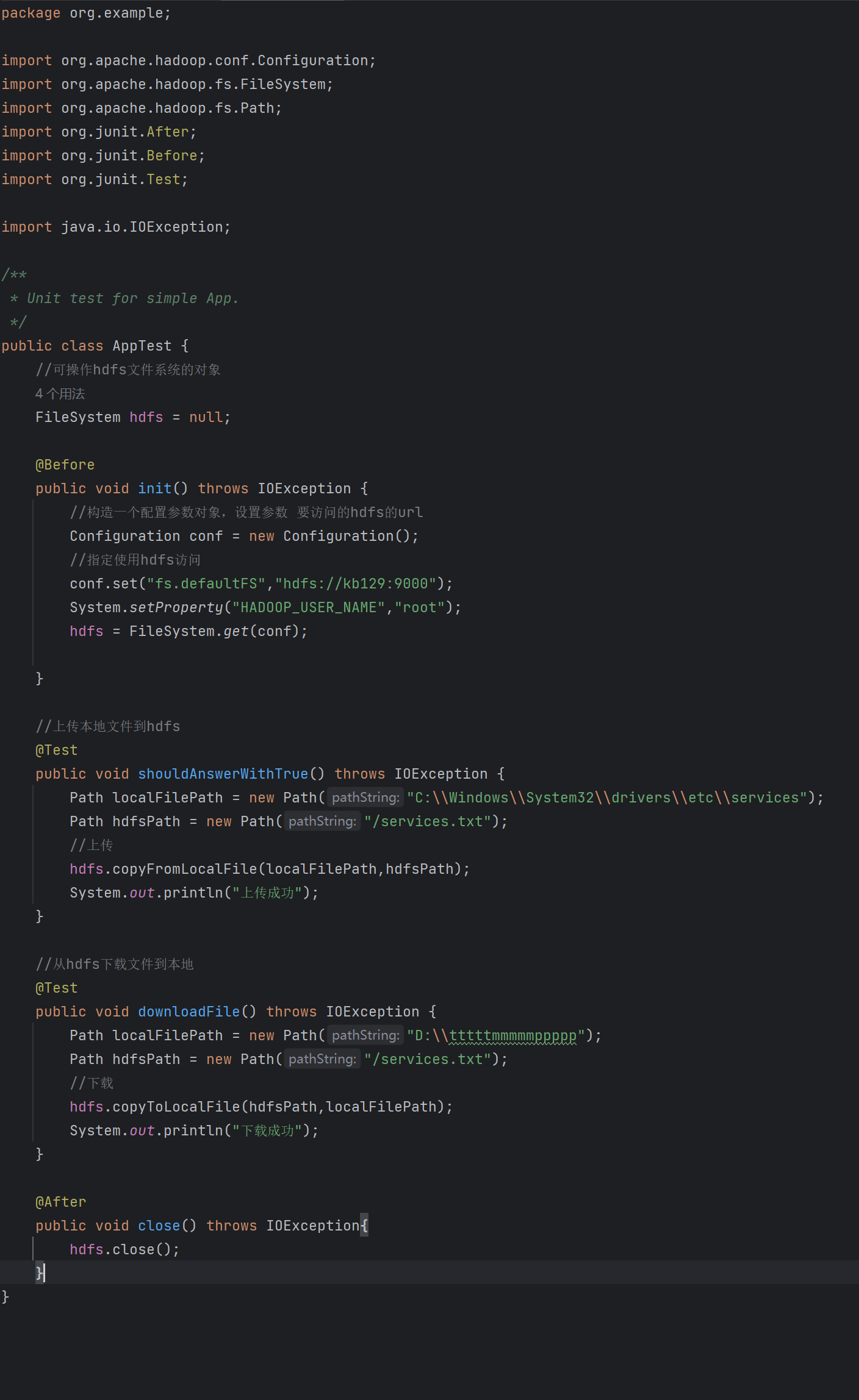
| 4.2 test包中重写AppTest
|