政府门户网站建设提升方案热点事件营销案例
使用K-Nearest Neighbors (KNN)算法进行分类。首先加载一个数据集,然后进行预处理,选择最佳的K值,并训练一个KNN模型。
# encoding=utf-8
import numpy as np
datas = np.loadtxt('datingTestSet2.txt') # 加载数据集,返回一个numpy数组
# 提取特征和标签
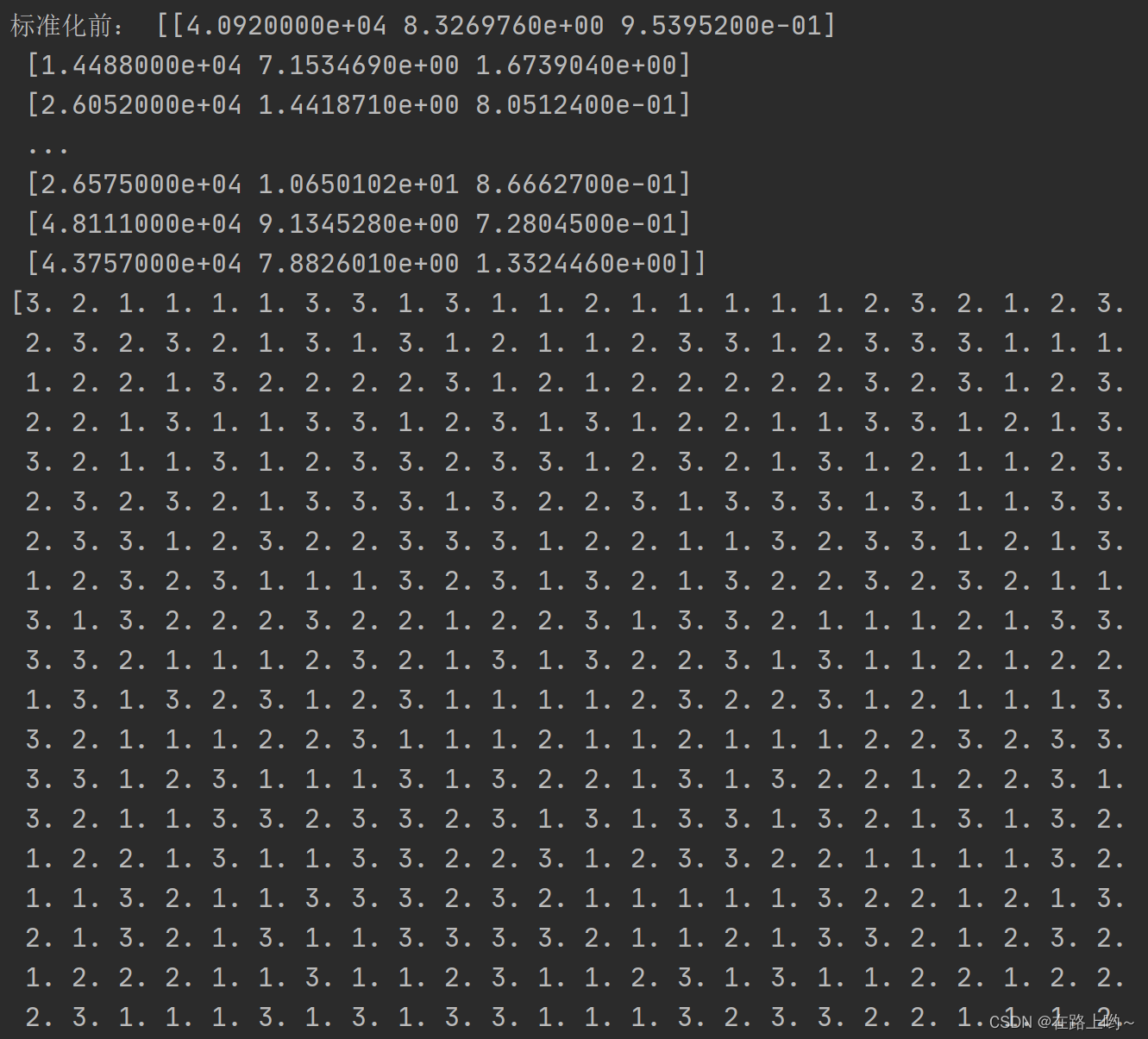
x_data = datas[:, 0:3] # 提取前三列数据作为特征
y_data = datas[:, 3] # 提取第四列数据作为标签print('标准化前:', x_data) # 特征矩阵
print(y_data) # 标签向量# 数据maxmin标准化
from sklearn.preprocessing import MinMaxScaler # 用于数据的标准化std = MinMaxScaler() # 创建一个MinMaxScaler对象
x_data = std.fit_transform(x_data) # 标准化
print('标准化:', x_data)# 拆分数据集(训练集和测试集)
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2,
random_state=123) # 测试集占总数据的20%,随机种子设为123以保证结果的可重复性# 建立KNN模型
from sklearn.neighbors import KNeighborsClassifier
# 使用交叉验证法评估模型性能
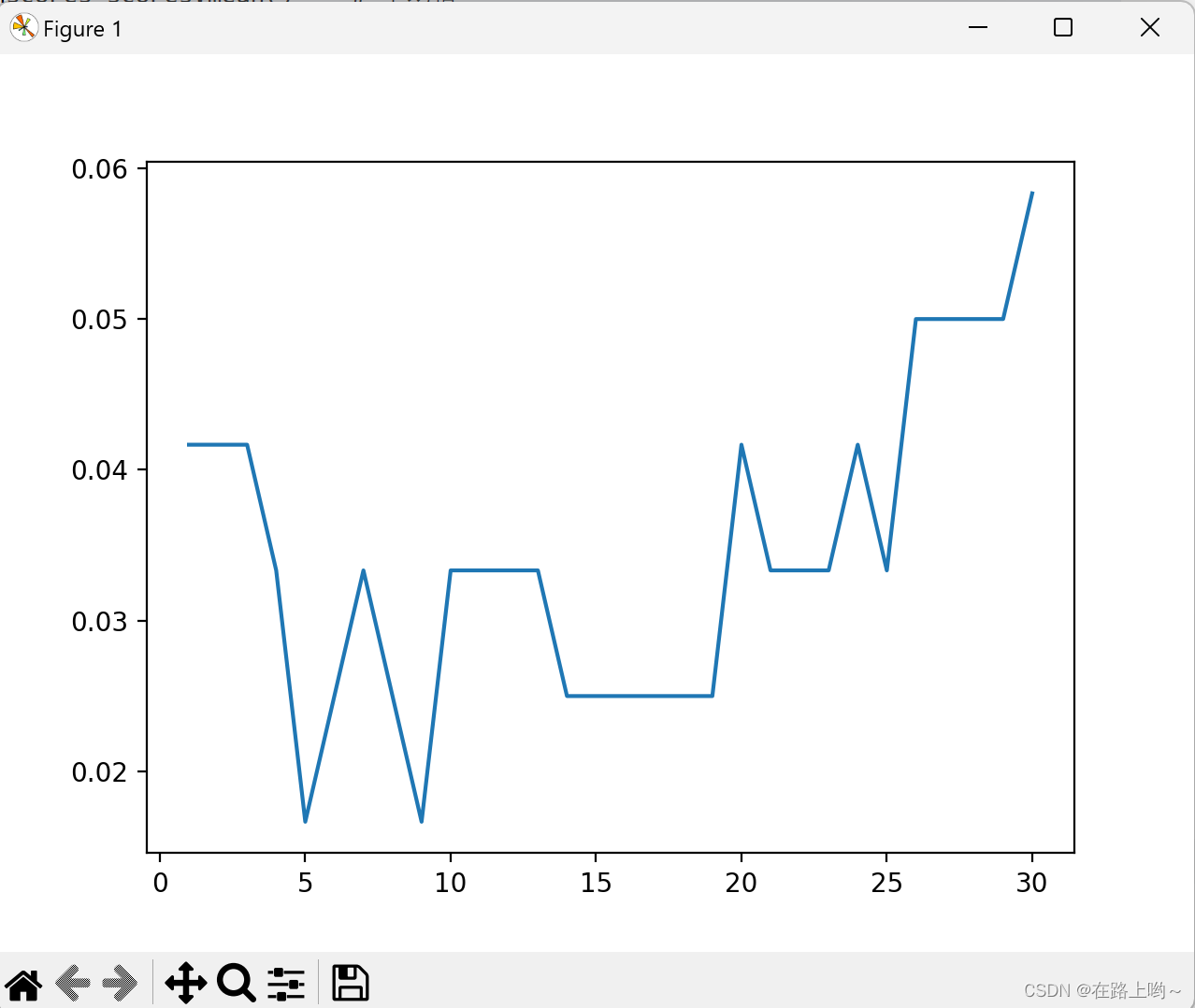
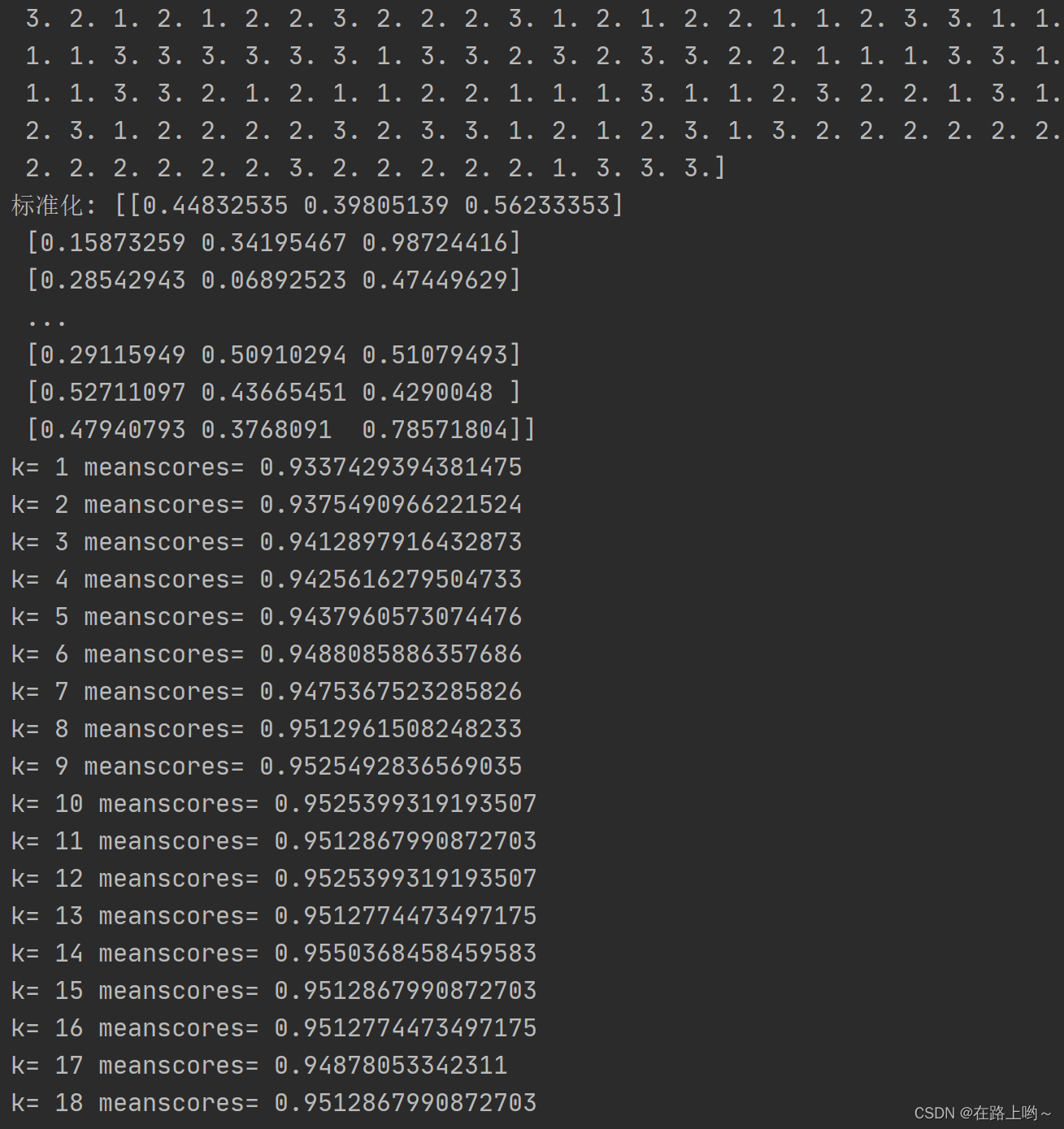
from sklearn.model_selection import cross_val_scorek_range = range(1, 31) # 创建一个范围从1到30的序列,用于试验不同的K值。
k_error = [] # 创建一个空列表,用于存储每个K值对应的错误率。# 找最合适的k,既平均值最高
for k in k_range:
model_kun = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(model_kun, x_train, y_train, cv=6, scoring="accuracy")# 将数据集分成6个子集
# 估计方法对象 数据特征 数据标签 几折交叉验证
meanscores = scores.mean() # 平均值
k_error.append(1 - meanscores) # 将准确率的平均值转换为错误率
print("k=", k, "meanscores=", meanscores)# 可视化K值和错误率的关系
import matplotlib.pyplot as pltplt.plot(k_range, k_error) # 绘制K值与错误率的图像
plt.show()# 建立KNN分类器模型,并使用训练集进行训练
model_kun = KNeighborsClassifier(n_neighbors=9) # n_neighbors=9表示在预测时,KNN分类器将考虑最近的9个邻居,并根据这9个邻居中最常见的类别来预测输入样本的类别model_kun.fit(x_train, y_train) # 使用训练集对模型进行训练
scores = model_kun.score(x_test, y_test) # 使用测试集评估模型性能,返回准确率
print('准确率为:', scores)


使用KNN算法加载鸢尾花数据集
# 加载鸢尾花数据集
from sklearn.datasets import load_irisiris = load_iris()
print(iris)
x_data = iris.data # 样本数据
y_data = iris.target # 标签数据
print("标准化前:", x_data)# 数据maxmin标准化
from sklearn.preprocessing import MinMaxScalermms = MinMaxScaler()
x_data = mms.fit_transform(x_data)
print(x_data)# 拆分数据集(训练集和测试集)
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2,random_state=123)# 建立knn模型
from sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import cross_val_scorek_range=range(1,31)
k_error=[] #错误率# 找最合适的k,既平均值最高
for k in k_range:model_kun=KNeighborsClassifier(n_neighbors=k)scores=cross_val_score(model_kun,x_train,y_train,cv=6,scoring="accuracy")# 估计方法对象 数据特征 数据标签 几折交叉验证meanscores=scores.mean() # 平均值k_error.append(1-meanscores) # 错误率print("k=",k,"meanscores=",meanscores)# 将k的值和错误率可视化出来,比较好找
import matplotlib.pyplot as plt
plt.plot(k_range,k_error)
plt.show()model_knn = KNeighborsClassifier(n_neighbors=10)model_knn.fit(x_train, y_train)
scores = model_knn.score(x_test, y_test) # 准确率
print(scores)