北京医疗网站建设网络营销的三大基础

《人工智能指数报告》由斯坦福大学、AI指数指导委员会及业内众多大佬Raymond Perrault、Erik Brynjolfsson 、James Manyika等人员和组织合著,旨在追踪、整理、提炼并可视化与人工智能(AI)相关各类数据,该报告已被大多数媒体及机构公认为最权威、最具信誉人工智能数据与洞察来源之一。
2024年版《人工智能指数报告》是迄今为止最为详尽的一份报告,包含了前所未有的大量原创数据,新增了对AI训练成本的估算、对负责任AI领域详尽分析,以及全新章节专门探讨人工智能对科学与医学的影响,充分体现了人工智能在我们生活各个领域日益凸显的重要性。
技术性能处于第二章节主要是回顾下现在的人工智能技术走了多远,从总体视角总结当前AI技术发展以及AI模型评估基准现状,再回到各个模态深入分析,以便于观察各个模型在不同课题面前的性能表现以及评估基准。

评估基准概览
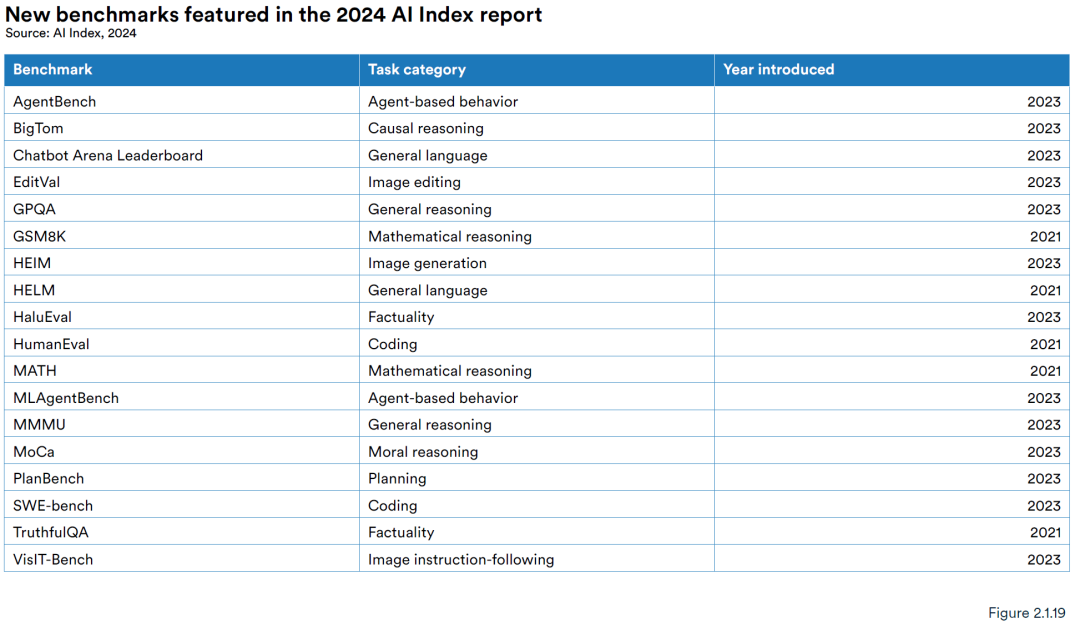
2023年有很多被废弃的指标也有很多新增的指标。整体而言一些新的具有挑战性的基准出现了,例如用于编程的SWE-bench、用于图像生成的HEIM、用于一般推理的MMMU、用于道德推理的MoCa以及用于基于代理的行为的AgentBench以及用于幻觉评估的HaluEval。

自然语言能力评估基准
自然语言处理 (NLP) 使计算机能够理解、解释、生成和转换文本。目前最先进的模型已能够生成流畅连贯的散文,并表现出高水平的语言理解能力。这个部分围绕着“理解力”,“语言生成”,“幻觉和真实性”的一些相关基准来观测AI技术现状。
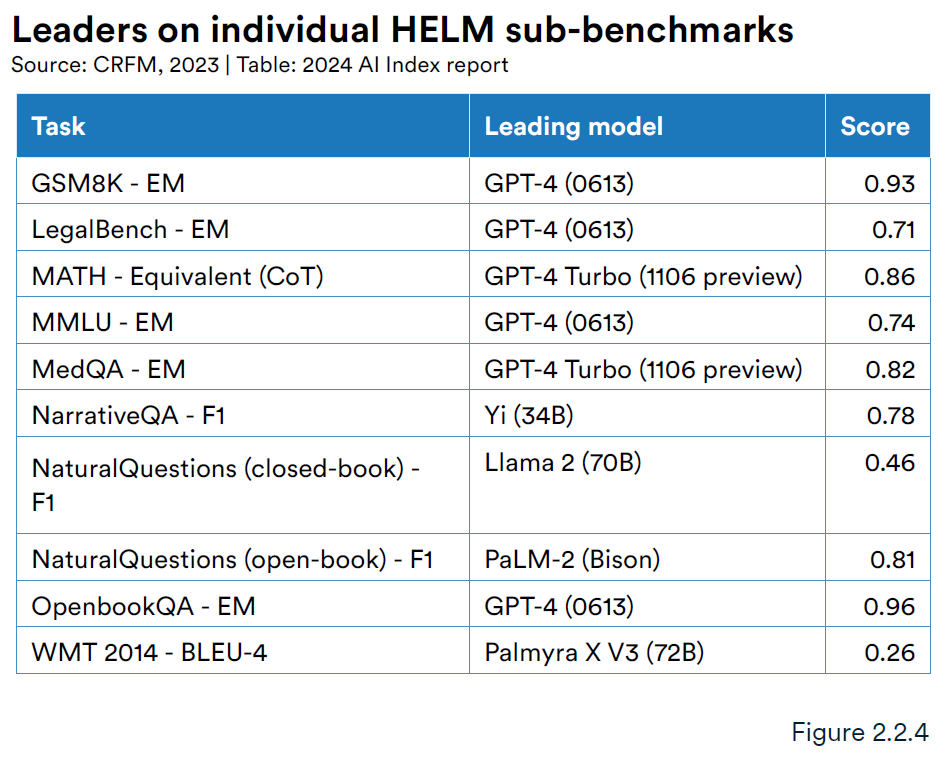
HELM是斯坦福推出,下图为各项子任务中得分较高的大模型
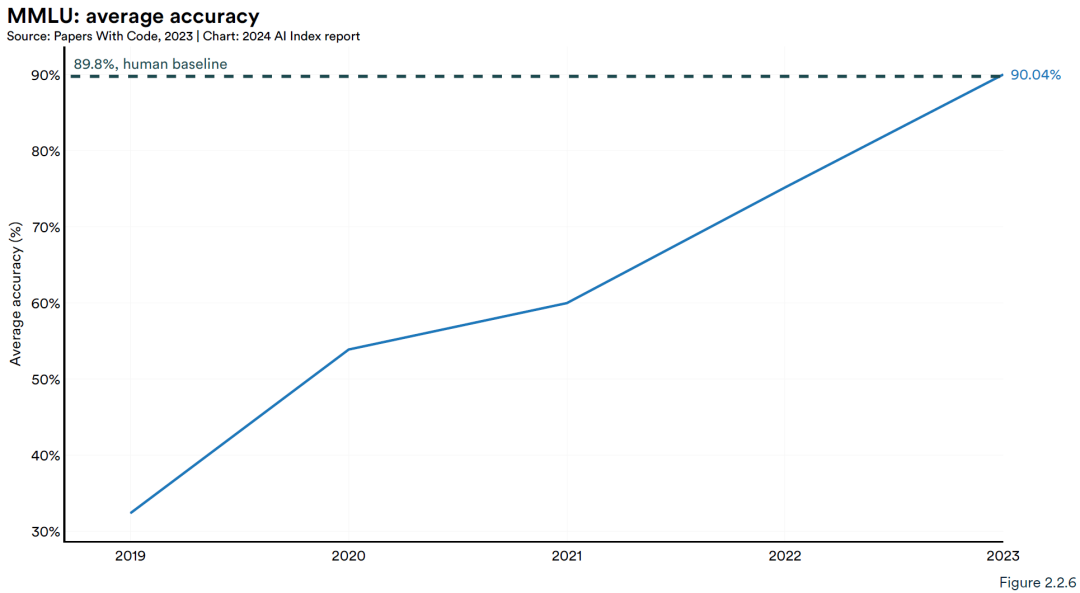
MMLU是多任务的语言理解,目前已经达到人类水准。MMLU 基准Gemini Ultra 以 90.0% 的最高分排名第一,率先超过了 MMLU 的人类基线 89.8%。
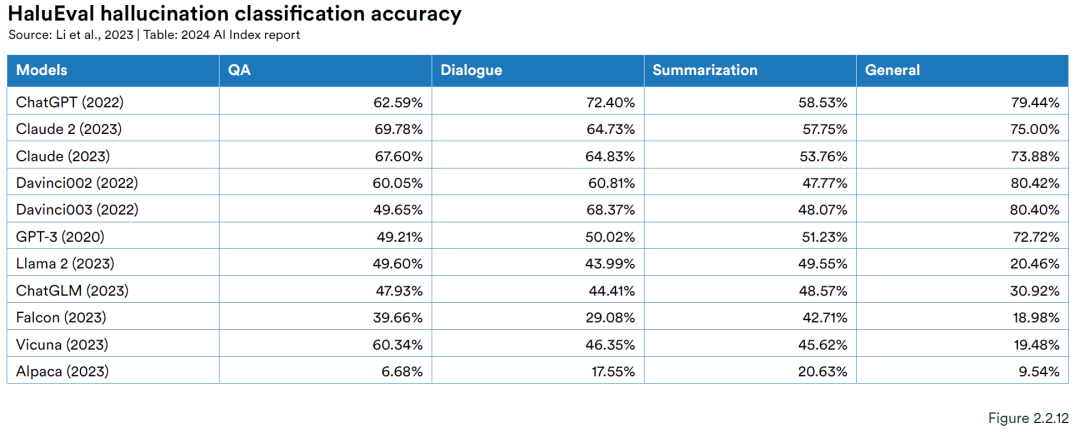
幻觉与真实性旨在LLM容易受到事实不准确和内容幻觉的影响,从而产生看似现实但虚假的信息。报告中TruthfulQA评估基准观察指出,较多大模型容易出现欠缺真实性的情况,但 2024年初发布的 GPT-4(RLHF)在 TruthfulQA基准测试中取得了迄今为止的最高成绩,得分为 0.6,比2021年GPT-2模型高出近三倍。

编码能力评估基准
HumanEval评估基准是用于评估对当前AI生成代码能力,由OpenAI研究人员于 2021年推出,由 164 个具有挑战性的手写编程问题组成。当前GPT-4模型变体 (AgentCoder) 在这个指标方面处于领先地位,得分为 96.3%。
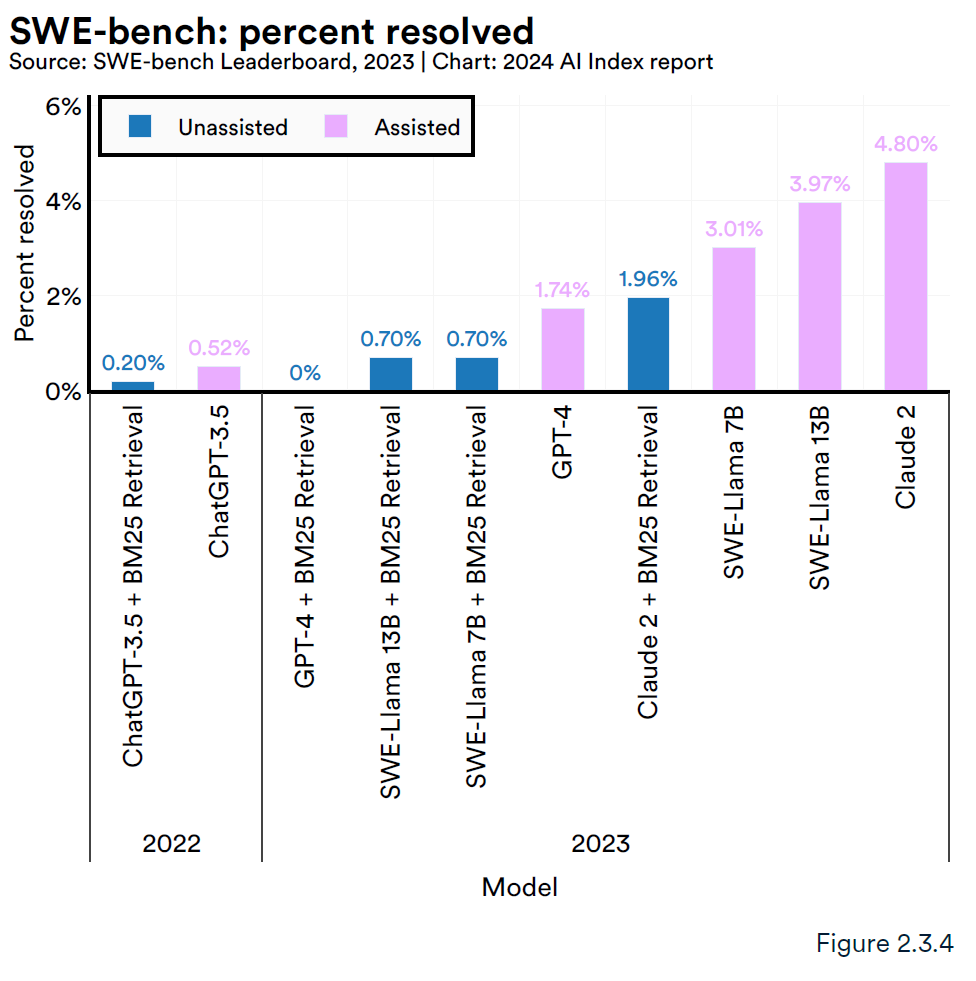
另外一种基于软件工程问题数据集的SWE-bench基准,对AI编码能力有着更严格的测试,例如,要求系统协调多个功能之间的更改,与各种执行环境交互,并执行复杂的推理。Claude 2在这个指标上表现最好,但是也仅仅解决了 4.8% 的问题。

视觉与图像生成评估基准
AIGC相关模态,分别从“图像生成”、“指令遵从”、“图像编辑“、“图片元素分割”、“二维转三维”的方面来评估当前AI的水平。
在图像生成方面,Midjourney模型从2022年至2024年几个迭代版本对“一幅哈利·波特的超写实图像”的指令而生成的图像。
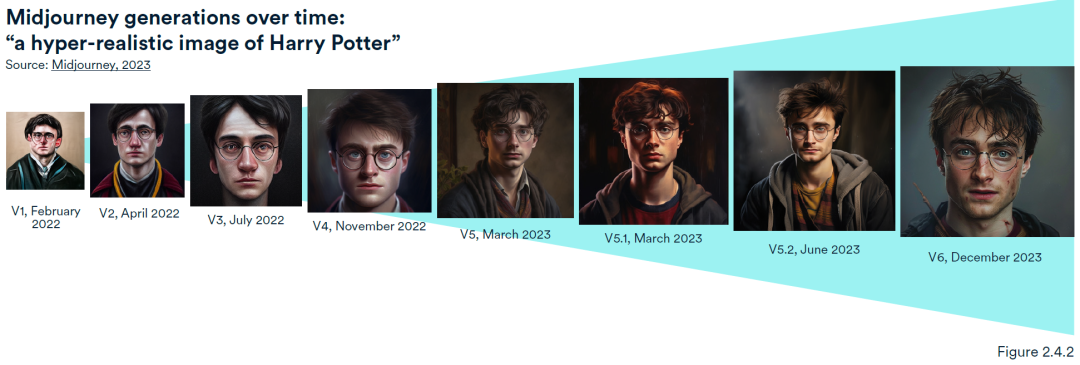
当前图像生成技术已经十分先进,生成的图与真是的图像时常无法区分。

HEIM,旨在全面评估图像生成器对实际部署至关重要的 12 个关键方面,例如图像-文本对齐、图像质量和美学。虽然没有一个模型在所有标准中都表现出色。但是在个别标准中还是有佼佼者的。比如,OpenAI的DALL-E 2对于评估生成的图像与输入文本的匹配程度得分最高。Stable Diffusion 的Dreamlike Photoreal在图像质量(衡量图像是否与真实照片相似)、美学(评估视觉吸引力)和原创性(衡量新颖图像生成和避免侵犯版权的指标)方面得分最高。

报告还提到了3D建模的图像技术,其中字节跳动和加州大学圣地亚哥分校的研究人员开发MVDream十分亮眼。

在指令遵循方面,VisIT-Bench评估基准用于观察模型基于文本指令生成图像的能力。VisIT-Bench,由592个具有挑战性的视觉语言指令组成,涵盖大约70个指令类别,例如情节分析、艺术知识和位置理解。截至2024年 1月,表现最好的是GPT-4Turbo的视觉变体,Elo得分为1,349。

在文本引导图片编辑改方面,报告指出其尚未有成熟的准确度评定方式,只是浅谈了EditVal评估基准。EditVal,包括超过 13 种编辑类型,例如添加对象或更改其位置,涵盖 19 个对象类。该基准测试用于评估八种领先的文本引导图像编辑方法,包括 SINE 和 Null-text。
下图为ControlNet和NeRF2NeRF




视频生成基准
旨在用文本或图片生成视频。报告采用了UCF101评估基准进行观察,今年的顶级模型W.A.L.T-XL取得了FVD16得分为36。值得注意的是,因为该模态有着其难题,例如大部分模型智能创建短小、低分辨率的视频,或者是生成的视频过于复杂而且训练数据集不理想导致模型表现不好等。这些问题报告介绍了“Align Your Latents”和“Emu Video”这些正在尝试克服这些问题的技术。
