如何做一名网站编辑百度网页游戏中心
去重基本原理
爬虫中什么业务需要使用去重
- 防止发出重复的请求
- 防止存储重复的数据
在爬取网页数据时,避免对同一URL发起重复的请求,这样可以减少不必要的网络流量和服务器压力,提高爬虫的效率,在将爬取到的数据存储到数据库或其他存储系统之前,去除重复的数据条目,确保数据的唯一性和准确性。,它不仅关系到数据的质量,也影响着爬虫的性能和效率。
根据给定的判断依据和给定的去重容器,将原始数据逐一进行判断,判断去重容器中是否有该数据。如果没有那就把该数据对应的判断依据添加去重容器中,同时标记该数据是不重复数据;如果有就不添加,同时标记该数据是重复数据。
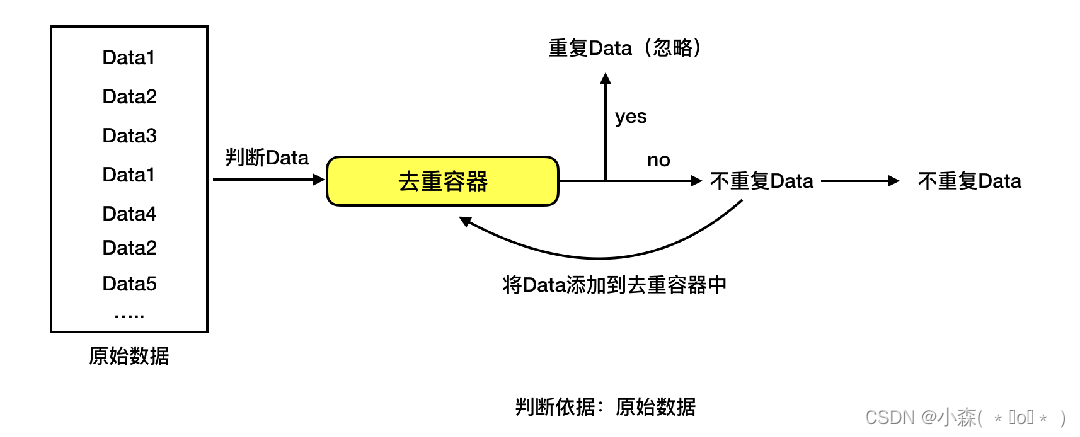
临时去重容器指如利用list、set等编程语言的数据结构存储去重数据,一旦程序关闭或重启后,去重容器中的数据就被回收了。使用与实现简单方便;但无法共享、无法持久化 持久化去重容器指如利用redis、mysql等数据库存储去重数据。
在爬虫中进行去重处理,可以使用信息摘要算法(如MD5、SHA1等)来实现。以下是一个简单的Python示例,使用MD5进行去重:
信息摘要hash算法
import hashlibdef md5_hash(text):md5 = hashlib.md5()md5.update(text.encode('utf-8'))return md5.hexdigest()def remove_duplicates(data_list):unique_list = []seen_hashes = set()for data in data_list:hash_value = md5_hash(data)if hash_value not in seen_hashes:seen_hashes.add(hash_value)unique_list.append(data)return unique_listdata_list = ['苹果', '香蕉', '橙子', '苹果', '橙子']
unique_list = remove_duplicates(data_list)
print(unique_list)在这个示例中,我们首先定义了一个md5_hash函数,用于计算给定文本的MD5哈希值。然后,我们定义了一个remove_duplicates函数,该函数接受一个数据列表,并使用一个集合seen_hashes来存储已经遇到的哈希值。对于列表中的每个数据项,我们计算其哈希值,如果该哈希值尚未出现在seen_hashes集合中,我们将其添加到集合中,并将数据项添加到结果列表unique_list中。最后,我们返回去重后的结果列表。
信息摘要hash算法指可以将任意长度的文本、字节数据,通过一个算法得到一个固定长度的文本。 如MD5(128位)、SHA1(160位)等。摘要算法主要用于比对信息源是否一致,因为只要源发生变化,得到的摘要必然不同;而且通常结果要比源短很多。
基于simhash算法的去重
- Simhash算法是一种用于文本相似度计算的哈希算法,可以用于去重处理。
- Simhash算法是一种局部敏感哈希算法,能实现相似文本内容的去重。
import jieba
from simhash import Simhashdef remove_duplicates(data_list):unique_list = []seen_hashes = set()for data in data_list:words = jieba.cut(data)simhash_value = Simhash(' '.join(words)).valueif simhash_value not in seen_hashes:seen_hashes.add(simhash_value)unique_list.append(data)return unique_listdata_list = ['苹果', '香蕉', '橙子', '苹果', '橙子']
unique_list = remove_duplicates(data_list)
print(unique_list)我们首先导入了jieba库(用于中文分词)和simhash库(用于计算Simhash值)。然后,我们定义了一个remove_duplicates函数,该函数接受一个数据列表,并使用一个集合seen_hashes来存储已经遇到的Simhash值。对于列表中的每个数据项,我们使用jieba库进行分词,然后计算其Simhash值。如果该Simhash值尚未出现在seen_hashes集合中,我们将其添加到集合中,并将数据项添加到结果列表unique_list中。最后,我们返回去重后的结果列表。
Simhash的特征
信息摘要算法:如果原始内容只相差一个字节,所产生的签名也很可能差别很大。
Simhash算法:如果原始内容只相差一个字节,所产生的签名差别非常小。
布隆过滤器
布隆过滤器是一种空间效率极高的概率型数据结构,用于判断一个元素是否可能在集合中。
网络爬虫: 网络爬虫在爬取网页数据时,需要避免爬取相同的URL地址。布隆过滤器可以用于存储已经访问过的URL,从而快速判断一个新的URL是否已经被爬取过,提高爬虫的效率。
反垃圾邮件:在反垃圾邮件系统中,布隆过滤器可以帮助快速判断一封邮件是否可能是垃圾邮件。通过将已知的垃圾邮件特征存储在布隆过滤器中,系统可以在数十亿个邮件列表中迅速识别出可能的垃圾邮件。
Web拦截器:在网络安全领域,布隆过滤器可以用作WEB拦截器,快速检查并拦截重复的恶意请求,防止网站被重复攻击。
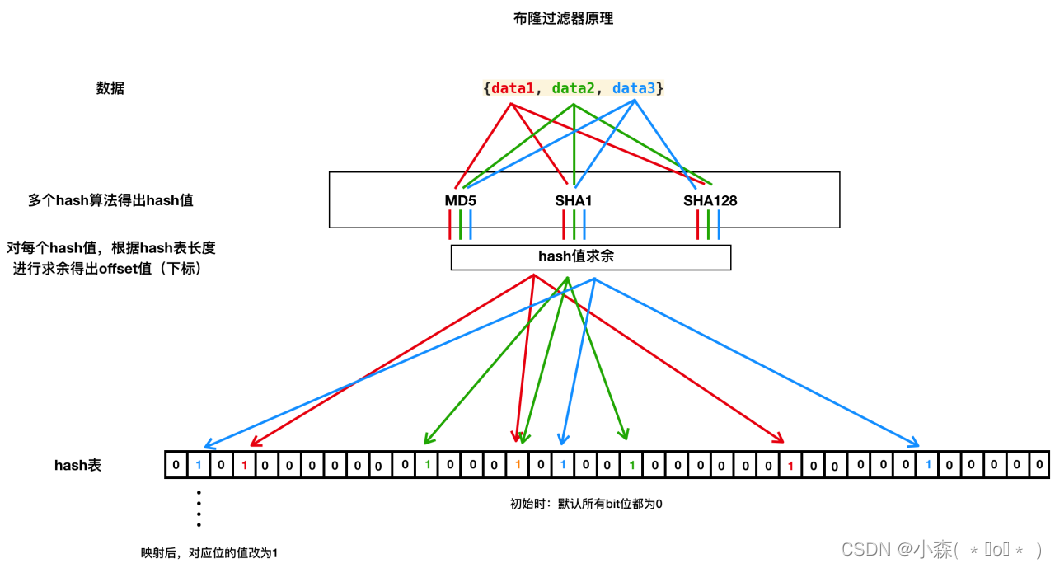
- 位数组初始化:布隆过滤器首先维护一个bitArray(位数组),在初始状态下所有数据都置为0。
- 使用多个哈希函数:当一个元素加入布隆过滤器时,会通过K个不同的哈希函数计算出K个哈希值,这些值对应到位数组中的K个位置,并将这些位置的值置为1。
- 误判率与数组大小:布隆过滤器存在一定的误判率,即可能会将不属于集合的元素误判为属于集合。降低误判率通常需要增大位数组的大小。
- 查询操作:进行查询时,同样使用那K个哈希函数计算待查询元素的哈希值,并检查位数组中对应的K个位置是否都为1。如果是,则认为元素可能在集合中;如果任一位不为1,则元素肯定不在集合中。
- 添加操作:向布隆过滤器中添加元素时,按照上述方法设置位数组中的相应位为1。由于位被设置为1后不会再变回0,所以布隆过滤器不支持删除操作。
- 实际应用:布隆过滤器常用于判断一个元素是否可能已经存在于一个大规模数据集中,例如网络爬虫中用于过滤已访问过的URL等场景。
- 性能优势:布隆过滤器的主要优点是空间效率和查询速度快,但它的缺点是不能保证100%的准确性,且无法删除元素。
- 优化措施:为了减少误判率,可以采用增加位数组大小、使用更多或更强的哈希函数等策略。同时,可以通过计数布隆过滤器等变种来支持元素的删除操作。
布隆过滤器是一种以空间换取时间效率的数据结构,适用于那些可以接受一定误判率但需要快速判断元素是否存在的场景。在设计布隆过滤器时,需要根据实际应用场景和可接受的误判率来选择合适的位数组大小和哈希函数数量。
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=1x4tmatnj0ypv