安康做企业网站的seo优化技术培训
wandb.sweep: 低代码,可视化,分布式 自动调参工具。
使用wandb 的 sweep 进行超参调优,具有以下优点。
(1)低代码:只需配置一个sweep.yaml配置文件,或者定义一个配置dict,几乎不用编写调参相关代码。
(2)可视化:在wandb网页中可以实时监控调参过程中每次尝试,并可视化地分析调参任务的目标值分布,超参重要性等。
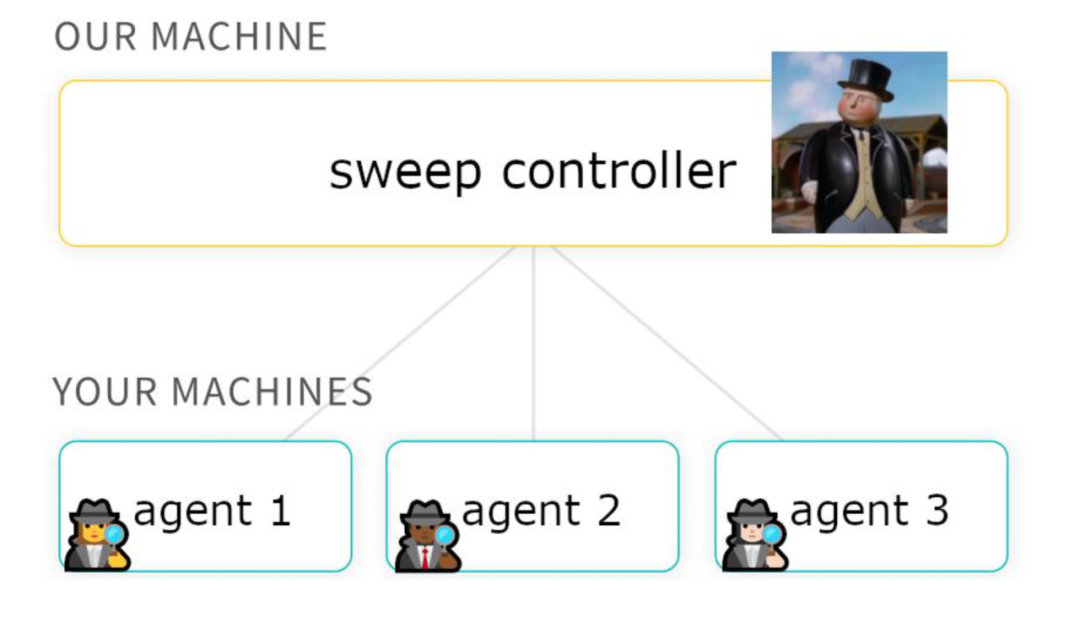
(3)分布式:sweep采用类似master-workers的controller-agents架构,controller在wandb的服务器机器上运行,agents在用户机器上运行,controller和agents之间通过互联网进行通信。同时启动多个agents即可轻松实现分布式超参搜索。
公众号后台回复关键词:wandb,获取本文notebook代码和B站视频演示。
使用 wandb 的sweep 调参的缺点:
需要联网:由于wandb的controller位于wandb的服务器机器上,wandb日志也需要联网上传,在没有互联网的环境下无法正常使用wandb 进行模型跟踪 以及 wandb sweep 可视化调参。
〇,使用Sweep的3步骤
配置 sweep_config
配置调优算法,调优目标,需要优化的超参数列表 等等。初始化 sweep controller:
sweep_id = wandb.sweep(sweep_config,project)启动 sweep agents:
wandb.agent(sweep_id, function=train)import os,PIL
import numpy as np
from torch.utils.data import DataLoader, Dataset
import torch
from torch import nn
import torchvision
from torchvision import transforms
import datetime
import wandb wandb.login()from argparse import Namespacedevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')#初始化参数配置
config = Namespace(project_name = 'wandb_demo',batch_size = 512,hidden_layer_width = 64,dropout_p = 0.1,lr = 1e-4,optim_type = 'Adam',epochs = 15,ckpt_path = 'checkpoint.pt'
)一. 配置 Sweep config
详细配置文档可以参考:https://docs.wandb.ai/guides/sweeps/define-sweep-configuration
1,选择一个调优算法
Sweep支持如下3种调优算法:
(1)网格搜索:grid. 遍历所有可能得超参组合,只在超参空间不大的时候使用,否则会非常慢。
(2)随机搜索:random. 每个超参数都选择一个随机值,非常有效,一般情况下建议使用。
(3)贝叶斯搜索:bayes. 创建一个概率模型估计不同超参数组合的效果,采样有更高概率提升优化目标的超参数组合。对连续型的超参数特别有效,但扩展到非常高维度的超参数时效果不好。
sweep_config = {'method': 'random'}2,定义调优目标
设置优化指标,以及优化方向。
sweep agents 通过 wandb.log 的形式向 sweep controller 传递优化目标的值。
metric = {'name': 'val_acc','goal': 'maximize' }
sweep_config['metric'] = metric3,定义超参空间
超参空间可以分成 固定型,离散型和连续型。
固定型:指定 value
离散型:指定 values,列出全部候选取值。
连续性:需要指定 分布类型 distribution, 和范围 min, max。用于 random 或者 bayes采样。
sweep_config['parameters'] = {}# 固定不变的超参
sweep_config['parameters'].update({'project_name':{'value':'wandb_demo'},'epochs': {'value': 10},'ckpt_path': {'value':'checkpoint.pt'}})# 离散型分布超参
sweep_config['parameters'].update({'optim_type': {'values': ['Adam', 'SGD','AdamW']},'hidden_layer_width': {'values': [16,32,48,64,80,96,112,128]}})# 连续型分布超参
sweep_config['parameters'].update({'lr': {'distribution': 'log_uniform_values','min': 1e-6,'max': 0.1},'batch_size': {'distribution': 'q_uniform','q': 8,'min': 32,'max': 256,},'dropout_p': {'distribution': 'uniform','min': 0,'max': 0.6,}
})4,定义剪枝策略 (可选)
可以定义剪枝策略,提前终止那些没有希望的任务。
sweep_config['early_terminate'] = {'type':'hyperband','min_iter':3,'eta':2,'s':3
} #在step=3, 6, 12 时考虑是否剪枝from pprint import pprint
pprint(sweep_config)二. 初始化 sweep controller
sweep_id = wandb.sweep(sweep_config, project=config.project_name)三, 启动 Sweep agent
我们需要把模型训练相关的全部代码整理成一个 train函数。
def create_dataloaders(config):transform = transforms.Compose([transforms.ToTensor()])ds_train = torchvision.datasets.MNIST(root="./mnist/",train=True,download=True,transform=transform)ds_val = torchvision.datasets.MNIST(root="./mnist/",train=False,download=True,transform=transform)ds_train_sub = torch.utils.data.Subset(ds_train, indices=range(0, len(ds_train), 5))dl_train = torch.utils.data.DataLoader(ds_train_sub, batch_size=config.batch_size, shuffle=True,num_workers=2,drop_last=True)dl_val = torch.utils.data.DataLoader(ds_val, batch_size=config.batch_size, shuffle=False, num_workers=2,drop_last=True)return dl_train,dl_valdef create_net(config):net = nn.Sequential()net.add_module("conv1",nn.Conv2d(in_channels=1,out_channels=config.hidden_layer_width,kernel_size = 3))net.add_module("pool1",nn.MaxPool2d(kernel_size = 2,stride = 2)) net.add_module("conv2",nn.Conv2d(in_channels=config.hidden_layer_width,out_channels=config.hidden_layer_width,kernel_size = 5))net.add_module("pool2",nn.MaxPool2d(kernel_size = 2,stride = 2))net.add_module("dropout",nn.Dropout2d(p = config.dropout_p))net.add_module("adaptive_pool",nn.AdaptiveMaxPool2d((1,1)))net.add_module("flatten",nn.Flatten())net.add_module("linear1",nn.Linear(config.hidden_layer_width,config.hidden_layer_width))net.add_module("relu",nn.ReLU())net.add_module("linear2",nn.Linear(config.hidden_layer_width,10))return netdef train_epoch(model,dl_train,optimizer):model.train()for step, batch in enumerate(dl_train):features,labels = batchfeatures,labels = features.to(device),labels.to(device)preds = model(features)loss = nn.CrossEntropyLoss()(preds,labels)loss.backward()optimizer.step()optimizer.zero_grad()return modeldef eval_epoch(model,dl_val):model.eval()accurate = 0num_elems = 0for batch in dl_val:features,labels = batchfeatures,labels = features.to(device),labels.to(device)with torch.no_grad():preds = model(features)predictions = preds.argmax(dim=-1)accurate_preds = (predictions==labels)num_elems += accurate_preds.shape[0]accurate += accurate_preds.long().sum()val_acc = accurate.item() / num_elemsreturn val_accdef train(config = config):dl_train, dl_val = create_dataloaders(config)model = create_net(config); optimizer = torch.optim.__dict__[config.optim_type](params=model.parameters(), lr=config.lr)#======================================================================nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')wandb.init(project=config.project_name, config = config.__dict__, name = nowtime, save_code=True)model.run_id = wandb.run.id#======================================================================model.best_metric = -1.0for epoch in range(1,config.epochs+1):model = train_epoch(model,dl_train,optimizer)val_acc = eval_epoch(model,dl_val)if val_acc>model.best_metric:model.best_metric = val_acctorch.save(model.state_dict(),config.ckpt_path) nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')print(f"epoch【{epoch}】@{nowtime} --> val_acc= {100 * val_acc:.2f}%")#======================================================================wandb.log({'epoch':epoch, 'val_acc': val_acc, 'best_val_acc':model.best_metric})#====================================================================== #======================================================================wandb.finish()#======================================================================return model #model = train(config)一切准备妥当,点火🔥🔥。
# 该agent 随机搜索 尝试5次
wandb.agent(sweep_id, train, count=5)四,调参可视化和跟踪
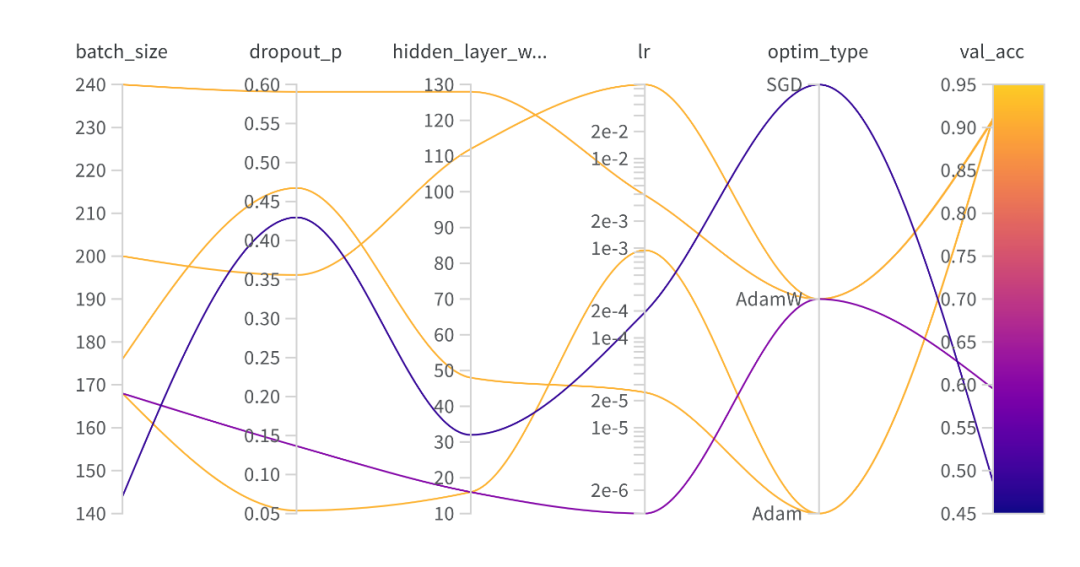
1,平行坐标系图
可以直观展示哪些超参数组合更加容易获取更好的结果。
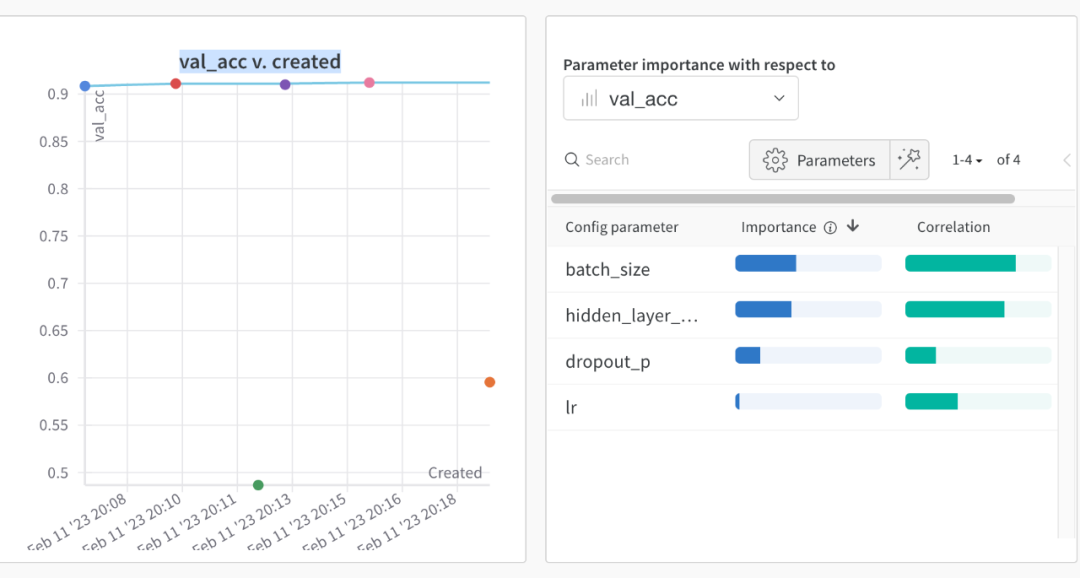
2,超参数重要性图
可以显示超参数和优化目标最终取值的重要性,和相关性方向。