网站建设注意专业优化网站排名
1. 树形结构
树形结构,是指:数据元素之间的关系像一颗树的数据结构。由树根延伸出多个树杈
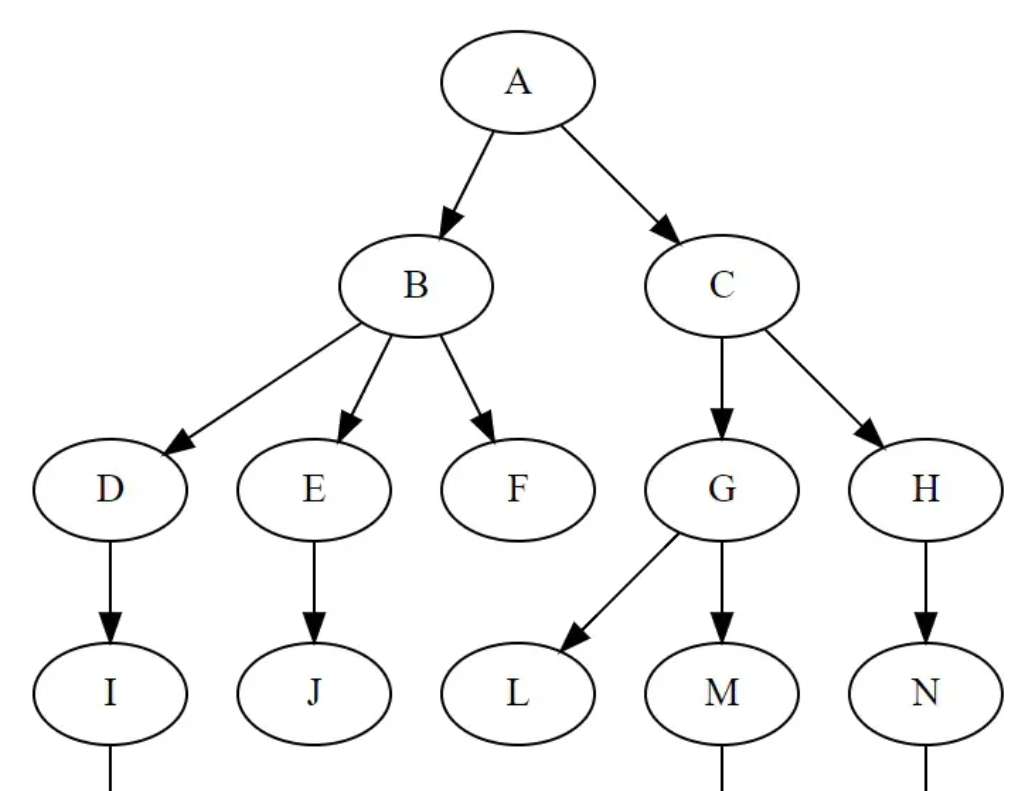
它具有以下特点:
- 每个节点都只有有限个子节点或无子节点;
- 没有父节点的节点称为根节点;
- 每一个非根节点有且只有一个父节点;
- 除了根节点外,每个子节点可以分为多个不相交的子树;
- 树里面没有环路(cycle)
2. 常见问题
在实际开发中,很多数据都是树形结构,例如:地区、页面上的菜单、上下级关系的组织等等,这时就需要我们从数据源中读取到数据,通过某些方式拼成树形结构 然后再给前端展示。对于一些不经常变化且使用频繁的数据,可以考虑将拼好的树形结构数据放入缓存,每次用的时候直接读取出来就可以使用。
3. 准备环境
springboot: 2.6.0
mysql: 5.7
CREATE TABLE `t_region` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`name` varchar(100) DEFAULT NULL,`region_type` varchar(255) DEFAULT NULL,`parent_id` bigint(20) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;INSERT into t_region(name, region_type, parent_id) VALUES('山西省', 'province', 0);
INSERT into t_region(name, region_type, parent_id) VALUES('临汾市', 'city', 1);
INSERT into t_region(name, region_type, parent_id) VALUES('尧都区', 'district', 2);INSERT into t_region(name, region_type, parent_id) VALUES('北京', 'province', 0);
INSERT into t_region(name, region_type, parent_id) VALUES('北京市', 'city', 4);
INSERT into t_region(name, region_type, parent_id) VALUES('朝阳区', 'district', 5);INSERT into t_region(name, region_type, parent_id) VALUES('太原市', 'city', 1);
INSERT into t_region(name, region_type, parent_id) VALUES('小店区', 'district', 7);
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>spring-test</artifactId><version>1.0-SNAPSHOT</version><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.0</version><relativePath/></parent><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.2</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.16.10</version><scope>provided</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.10</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!-- druid依赖 --><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.0</version></dependency></dependencies>
</project>
spring:main:allow-circular-references: truedatasource: #定义数据源#127.0.0.1为本机测试的ip,3306是mysql的端口号。serverTimezone是定义时区,照抄就好,mysql高版本需要定义这些东西#useSSL也是某些高版本mysql需要问有没有用SSL连接url: jdbc:mysql://192.168.1.141:3306/db_user?serverTimezone=GMT%2B8&useSSL=FALSEusername: root #数据库用户名,root为管理员password: 123456 #该数据库用户的密码# 使用druid数据源type: com.alibaba.druid.pool.DruidDataSource
mybatis-plus:# xml扫描,多个目录用逗号或者分号分隔(告诉 Mapper 所对应的 XML 文件位置)mapper-locations: classpath:mapper/*.xml# 以下配置均有默认值,可以不设置global-config:db-config:#主键类型 AUTO:"数据库ID自增" INPUT:"用户输入ID",ID_WORKER:"全局唯一ID (数字类型唯一ID)", UUID:"全局唯一ID UUID";id-type: auto#数据库类型db-type: MYSQLconfiguration:# 是否开启自动驼峰命名规则映射:从数据库列名到Java属性驼峰命名的类似映射map-underscore-to-camel-case: true# 如果查询结果中包含空值的列,则 MyBatis 在映射的时候,不会映射这个字段call-setters-on-nulls: true# 这个配置会将执行的sql打印出来,在开发或测试的时候可以用log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
表对应的实体类
@Data
@TableName(value = "t_region")
public class Region {@TableId(type = IdType.AUTO)private Long id;/*** 名称*/private String name;/*** 类型*/private String regionType;/*** 父id*/private Long parentId;
}
返回给前端的实体类
@Data
public class RegionVO {private Long id;/*** 名称*/private String name;/*** 类型*/private String regionType;/*** 父id*/private Long parentId;private List<RegionVO> children;
}
4.实现方式
1.基于xml
RegionMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.example.mapper.RegionMapper"><resultMap id="regionMap" type="org.example.dto.RegionVO"><id property="id" column="id"></id><result property="name" column="name"></result><result property="regionType" column="region_type"></result><result property="parentId" column="parent_id"></result><collection property="children" ofType="org.example.dto.RegionVO" javaType="java.util.List"column="id" select="getById"></collection></resultMap><select id="getById" resultMap="regionMap" parameterType="map">SELECT*FROMt_regionwhere parent_id=#{id}</select><select id="getAll" resultMap="regionMap">SELECT*FROMt_region where parent_id = 0</select></mapper>RegionMapper
@Mapper
public interface RegionMapper extends BaseMapper<Region> {List<RegionVO> getAll();
}
RegionService
public interface RegionService extends IService<Region> {List<RegionVO> getAll();
}
RegionServiceImpl
@Service
public class RegionServiceImpl extends ServiceImpl<RegionMapper, Region> implements RegionService {@Overridepublic List<RegionVO> getAll(){return baseMapper.getAll();}
}
这种方式按照上边添加的数据量(8条)共执行了9次查询

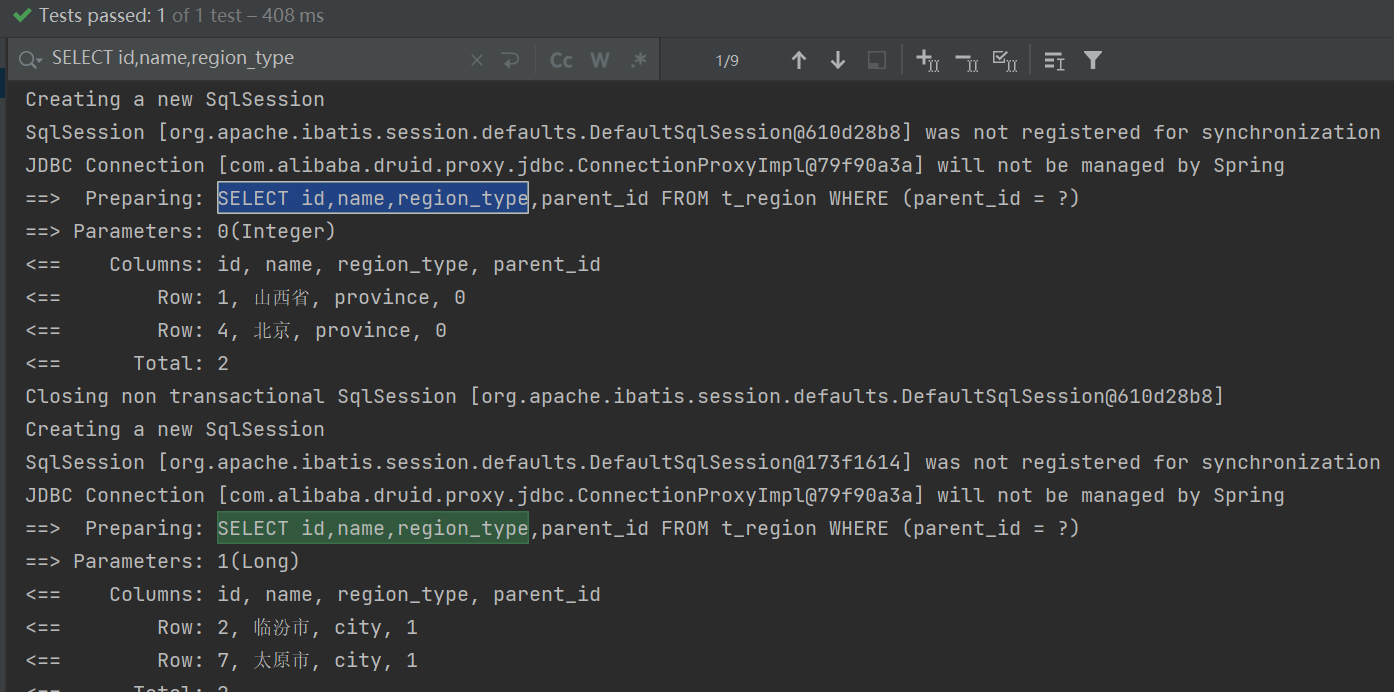
2.LambdaQueryWrapper
RegionServiceImpl添加如下代码
@Overridepublic List<RegionVO> getAllWrapper(){LambdaQueryWrapper<Region> wrapper = new LambdaQueryWrapper<>();wrapper.eq(Region::getParentId, 0);//查询根级List<Region> regions = baseMapper.selectList(wrapper);List<RegionVO> list = regions.stream().map(p -> {RegionVO obj = new RegionVO();BeanUtils.copyProperties(p, obj);return obj;}).collect(Collectors.toList());list.forEach(this::getChildren);return list;}private void getChildren(RegionVO item){LambdaQueryWrapper<Region> wrapper = new LambdaQueryWrapper<>();wrapper.eq(Region::getParentId, item.getId());//根据parentId查询List<Region> list = baseMapper.selectList(wrapper);List<RegionVO> voList = list.stream().map(p -> {RegionVO vo = new RegionVO();BeanUtils.copyProperties(p, vo);return vo;}).collect(Collectors.toList());//写入到childrenitem.setChildren(voList);//如果children不为空,继续往下找if (!CollectionUtils.isEmpty(voList)) {voList.forEach(this::getChildren);}}
这种方式按照上边添加的数据量(8条)共执行了9次查询
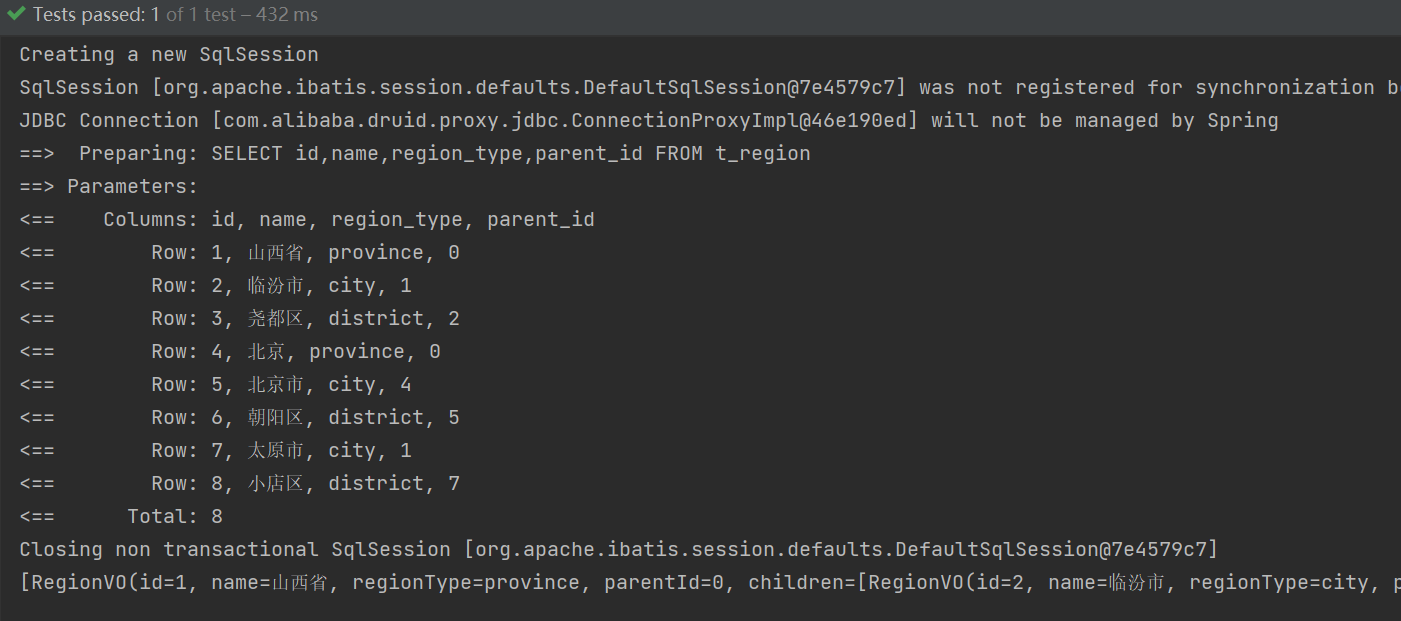
3.递归方法
RegionServiceImpl添加如下代码
@Override
public List<RegionVO> build(){//一次把所有的数据都查出来List<Region> regions = baseMapper.selectList(null);List<RegionVO> allList = regions.stream().map(p -> {RegionVO vo = new RegionVO();BeanUtils.copyProperties(p, vo);return vo;}).collect(Collectors.toList());//指定根节点的parentIdreturn buildChildren(0L, allList);
}private List<RegionVO> buildChildren(Long parentId, List<RegionVO> allList){List<RegionVO> voList = new ArrayList<>();for (RegionVO item : allList) {//如果相等if (Objects.equals(item.getParentId(), parentId)) {//递归,自己调自己item.setChildren(buildChildren(item.getId(), allList));voList.add(item);}}return voList;
}
这种就不必说了,一次查询所有数据出来,一共执行一次查询
4.总结
查询方式有很多,应该使用哪种需要猿们结合具体情况选择。
第一种情况:当整体数据量特别大 层级不深 需要按照某个根节点查询时,推荐使用第一、二种方式。
第二种情况:当需要查询整个树时,推荐使用第三种方式。