云南做商城网站多少钱做推广怎么赚钱
TF-IDF (Term Frequency-Inverse Document Frequency) 是一种用于信息检索与文本挖掘的统计方法,用来评估一个词对于一个文件集或一个语料库中的其中一份文件的重要性。它是一种常用于文本处理和自然语言处理的权重计算技术。
原理
TF-IDF 由两部分组成:词频(TF),文档频率(DF)和逆文档频率(IDF)。每一部分的计算方法如下:
-
词频(TF, Term Frequency):指某一个给定的词语在该文件中出现的频率。这个数字通常会被标准化(通常是词频除以文章总词数),以防止它偏向长的文件。(即使某一特定的词语在长文件中出现频率较高,其实该词语可能并不重要。

-
文档频率(DF): 是文本挖掘和信息检索中的一个基本概念,特别是在计算 TF-IDF(词频-逆文档频率) 时经常被用到。尽管通常在TF-IDF计算中讨论DF的倒数,但单独理解它也同样重要。定义为包含词 t 的文档数目,在语料库 D 中。它衡量一个词在整个语料库中的普遍性或稀有性。
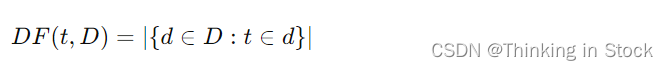
-
逆文档频率(IDF, Inverse Document Frequency):这是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:

-
TF-IDF:然后将TF和IDF相乘得到一个词的TF-IDF分数,该分数即为词在文档中的重要性:

比较TF-IDF与余弦相似度(Cosine Similarity),TF-IDF 主要用于调整词在文档中的权重,而余弦相似度是一种衡量两个文本向量方向相似度的方法。
TF-IDF
目的:
- 权重调整:TF-IDF 通过增加罕见词的权重而降低常见词的权重,从而提供了一种评估词语在一个或多个文档中重要性的方法。
优点:
- 区分文档特有的重要词汇:对于只在少数文档中出现,但在这些文档中出现频率较高的词,TF-IDF 会赋予较高的权重。
局限性:
- 无法直接用于相似性度量:TF-IDF 本身是一个用于调整单词权重的统计方法,它需要与其他技术(如余弦相似度)结合使用,才能用于文档相似性度量。
余弦相似度
目的:
- 相似性度量:余弦相似度通过计算两个向量之间的角度余弦值来度量它们的相似度,用于比较两个文本向量的方向一致性。
优点:
- 规模不变性:余弦相似度衡量的是方向一致性而非向量的大小,因此它对文本长度不敏感,适用于比较长度不同的文档。
- 直观度量相似性:可以直接用于评估两个文本的相似度,特别是结合了TF-IDF后,可以有效反映出文本内容的语义相似性。
局限性:
- 依赖于向量表达:余弦相似度的效果很大程度上依赖于文本向量的构建方式(如使用TF-IDF或其他词向量模型)。
结合使用 TF-IDF 和 余弦相似度
在实际应用中,TF-IDF 通常与余弦相似度结合使用来提高文本相似性度量的准确性:
- 向量化:首先使用 TF-IDF 对文档中的每个词进行权重计算,生成文档的向量表示。
- 相似性计算:然后计算这些基于 TF-IDF 的向量之间的余弦相似度,以确定文档间的相似性。
下面看下TF-IDF代码实现:
import numpy as np
from collections import defaultdict
import math# 示例语料库
documents = ["the sky is blue","the sun is bright","the sun in the sky is bright","we can see the shining sun, the bright sun"
]# 计算词频的函数
def compute_tf(text):# 将文本分割为词项terms = text.split()tf_data = {}for term in terms:tf_data[term] = tf_data.get(term, 0) + 1# 按文档中的总词数进行标准化total_terms = len(terms)for term in tf_data:tf_data[term] = tf_data[term] / total_termsreturn tf_data# 计算逆文档频率的函数
def compute_idf(documents):N = len(documents)idf_data = defaultdict(lambda: 0)for document in documents:terms = set(document.split())for term in terms:idf_data[term] += 1# 计算IDFfor term, count in idf_data.items():idf_data[term] = math.log(N / float(count))return idf_data# 计算TF-IDF的函数
def compute_tfidf(documents):# 计算各个文档的TFtfs = [compute_tf(doc) for doc in documents]# 计算语料库的IDFidfs = compute_idf(documents)# 计算TF-IDFtf_idf = []for doc_tf in tfs:doc_tf_idf = {}for term, value in doc_tf.items():doc_tf_idf[term] = value * idfs[term]tf_idf.append(doc_tf_idf)return tf_idf# 为语料库计算TF-IDF
tf_idf_scores = compute_tfidf(documents)# 输出结果
for idx, doc_scores in enumerate(tf_idf_scores):print(f"文档 {idx + 1} 的TF-IDF分数:")for term, score in doc_scores.items():print(f" {term}: {score:.4f}")
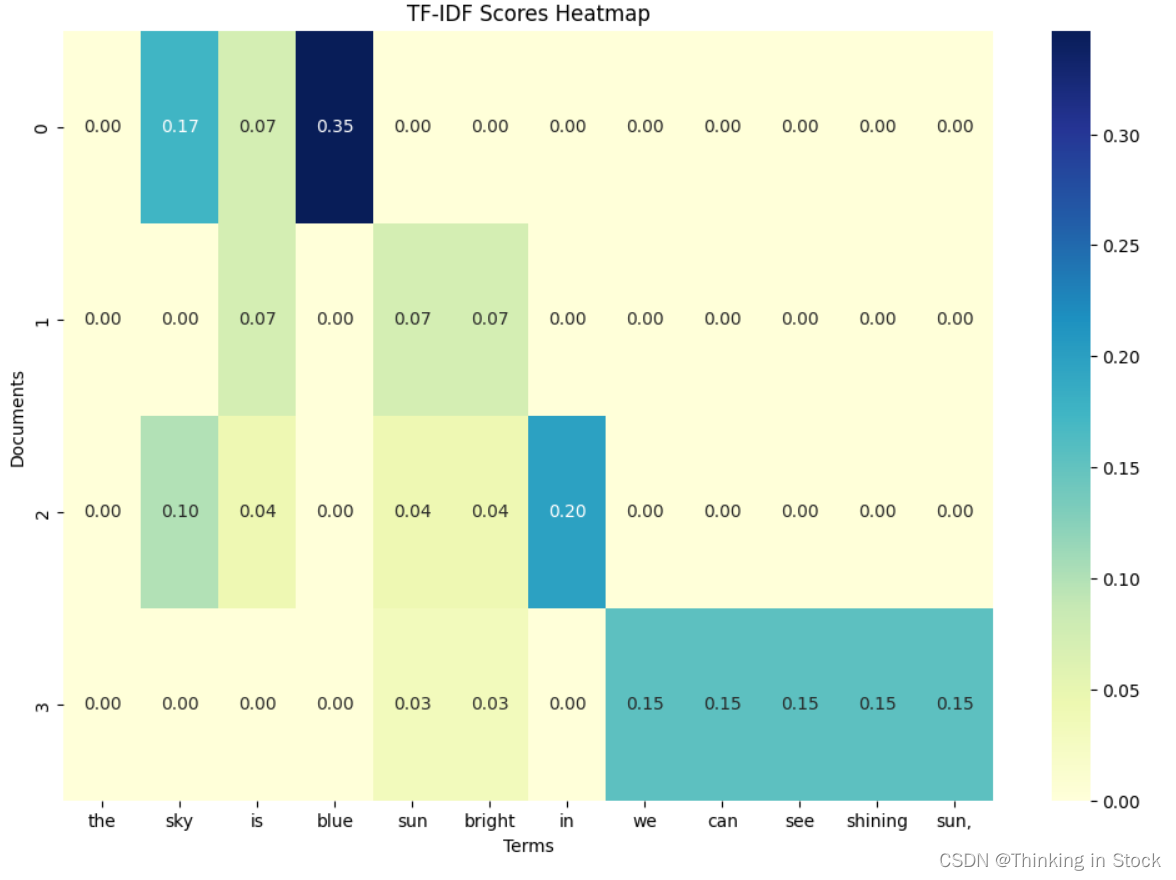
创建Heatmap显示单词在各个文档中的权重:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Create a DataFrame from the TF-IDF dictionary
tf_idf_df = pd.DataFrame(tf_idf_scores)
tf_idf_df = tf_idf_df.fillna(0) # Fill NaN values with 0# Create a heatmap
plt.figure(figsize=(12, 8))
sns.heatmap(tf_idf_df, annot=True, cmap="YlGnBu", fmt=".2f")
plt.title('TF-IDF Scores Heatmap')
plt.xlabel('Terms')
plt.ylabel('Documents')
plt.show()