深圳网站建设深圳网络网站推广包括
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖
掘,信息处理或存储历史数据等一系列的程序中。
1. 安装scrapy:
pip install scrapy
注意:需要安装在python解释器相同的位置,例如:D:\Program Files\Python3.11.4\Scripts
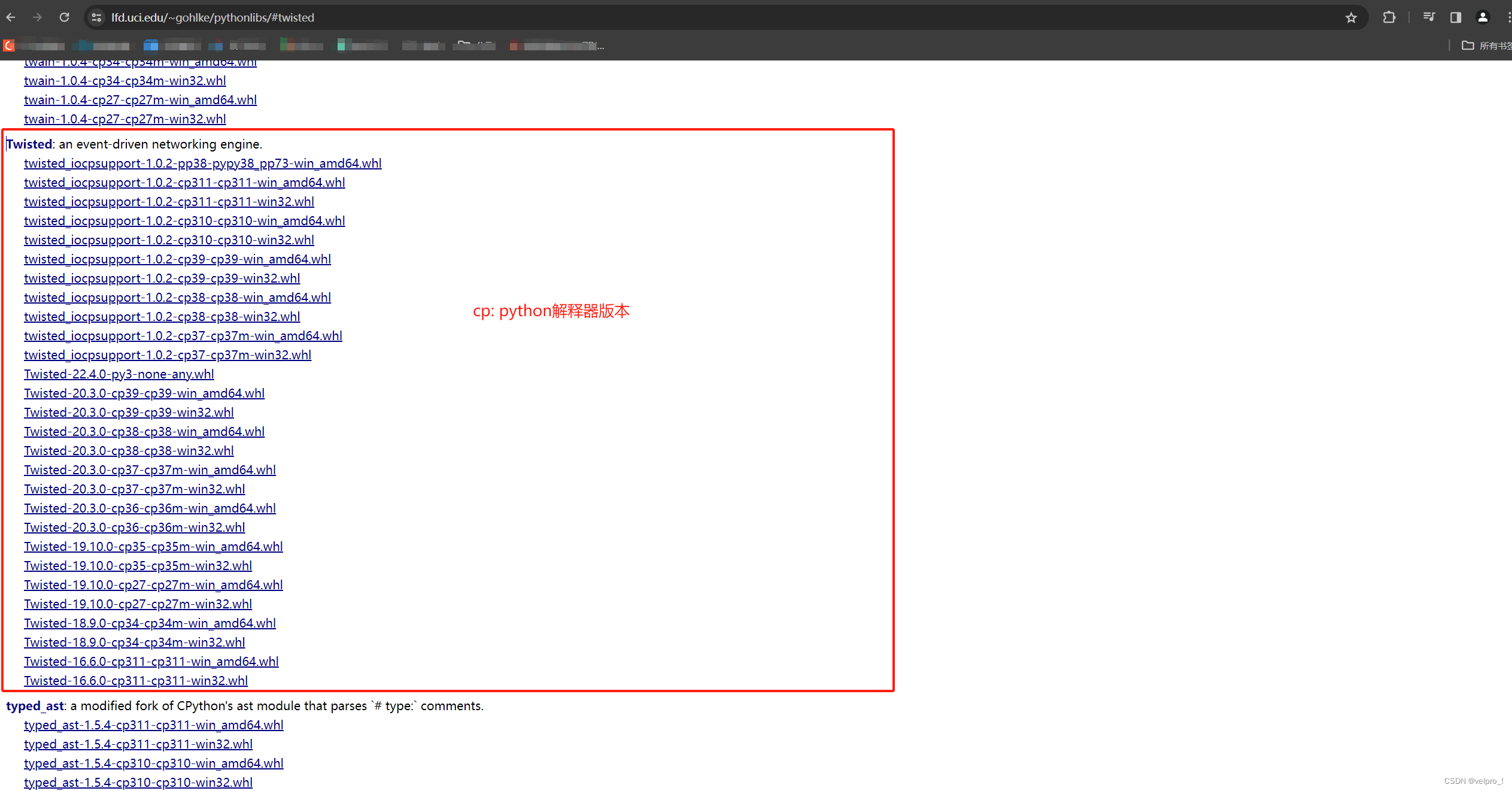
若安装时报错缺少twisted,解决方法:安装twisted合适的版本 twisted下载路径
下载 twisted后,安装twisted:pip install twisted路径
 查看python版本:终端输入python
查看python版本:终端输入python

若报错win32错误,解决方法:pip install pypiwin32
若是仍然报错,可安装anaconda,若使用anaconda,pycharm里的解释器也需要换成anaconda的的路径 Anaconda 安装
(注意:安装anaconda时,安装路径下不能有任何文件,否则可能会导致不能用 )
2. 使用scrapy创建项目:
scrapy startproject 项目名字 (项目名字不能用数字开头,不能包含中文)

项目结构: spidersinit_.py自定义的爬虫文件.py ---》由我们自己创建,是实现爬虫核心功能的文件 init__.py items.py ---》定义数据结构的地方(爬取的数据有哪些),是一个继承自 scrapy.Item的类 middlewares.py ---》中间件 代理 pipelines.py ---》管道文件,里面只有一个类,用于处理下载数据的,后续处理默认是300优先级,值越小优先级越高 (1-10) settings.py ---》配置文件 比如: 是否遵守robots协议,user-Agent定义等
3. 创建爬虫文件
在spiders下创建,进入spiders目录: cd .\项目名字\项目名字\spiders
scripy genspider 爬虫文件的名字 要爬取的网页 (一般情况下不需要添加http协议)

4. 运行爬虫程序
scrapy crawl 爬虫的名字 (名字为程序中的name)

例子:
# spider下的爬虫文件
import scrapyclass TongchengSpider(scrapy.Spider):name = "tongcheng"allowed_domains = ["https://sz.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=classify_E%2Cuuid_YZWJGz6dw5SYe54A6jYeyfiY5J4TPdc8&search_uuid=YZWJGz6dw5SYe54A6jYeyfiY5J4TPdc8&search_type=input"]start_urls = ["https://sz.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=classify_E%2Cuuid_YZWJGz6dw5SYe54A6jYeyfiY5J4TPdc8&search_uuid=YZWJGz6dw5SYe54A6jYeyfiY5J4TPdc8&search_type=input"]def parse(self, response):print("学习scrapy")content = response.text # 获取的是响应的字符串content1 = response.body # 获取的是二进制数据# span = response.xpath("xpath语法") # 可以直接是xpath方法来解析response中的内容span = response.xpath('//div[@id="filter"]/div[@class="tabs"]/a/span')[0] # xpathprint("=================================================================")print(span.extract()) # 提取seletor对象的data的属性值print(span.extract_first()) # 提取的seletor列表的第一个数据