春晗环境建设有限公司网站seo百度排名优化
Redis的使用场景
Redis(Remote Dictionary Server)是一个内存数据结构存储系统,它以快速、高效的特性闻名,并且它支持多种数据结构,包括字符串、哈希表、列表、集合、有序集合等。它主要用于以下场景:
- 缓存: Redis最常见的用途之一是作为缓存层,用来存储经常访问但计算成本较高的数据(如,数据库查询结果、API调用结果等)。将数据存储在Redis的内存中,可以加速对数据的访问,降低后端系统的负载,提升应用层的相应速度;
- 分布式锁: Redis提供了分布式锁机制,可以用来解决分布式系统中的并发访问问题,开发者可以通过Redis的SETNX(SET if Not eXists)实现简单而高效的分布式锁。
- ……
Redis中可能面临的问题
- 作为缓存层可能面临的问题:穿透、击穿、雪崩、双写一致、持久化、数据过期、淘汰策略等;
- 在分布式系统中可能面临的问题:setnx、redisson
缓存穿透问题
带有缓存层的数据查询过程:

缓存穿透: 通常,缓存系统在接收到一个查询请求时,会首先检查缓存中是否已经存在相应的数据。如果存在,则直接返回缓存中的数据;如果不存在,则去底层存储系统(如数据库)查询数据,并将查询结果存入缓存中,以供后续请求使用。然而,当恶意用户或者系统频繁地查询不存在的数据时,缓存系统无法命中缓存,而每次请求都会直接访问底层存储系统,从而绕过了缓存系统,这种情况就称为缓存穿透。
原因: 可能是由于恶意攻击、缓存配置不当或者业务逻辑漏洞等。
解决方法:
- 空值缓存:在缓存中存储不存在的键对应的空值,即使查询不存在的数据也能命中缓存。这样可以减少对底层存储系统的频繁访问。
- 布隆过滤器:使用布隆过滤器来过滤掉不存在的查询请求,从而避免将无效的查询请求发送到底层存储系统。
- 缓存预热:在系统启动时或者定时任务中,预先加载热门数据到缓存中,以减少对底层存储系统的请求压力。
- 限流和监控:对请求频率进行限流,以防止恶意请求造成的缓存穿透问题,并通过监控系统实时监测缓存命中率和底层存储系统的负载情况,及时发现并解决问题。
方案一——空值缓存:
- 实现:缓存空数据,即查询返回的数据为空时,仍把这个空结果进行缓存
- 优点:简单
- 缺点:消耗内存(若查询的大量数据都为空,则缓存的压力会很大);可能会发生数据不一致问题(比如,最开始查询某个key对应的数据为空,但是后面在数据库中添加了该key所对应的数据,但缓存中的存储结果仍然为空,导致数据库和缓存中的数据不一致)
方案二——布隆过滤器:
带有布隆过滤器的请求过程通常涉及以下几个步骤:
- 发送查询请求:客户端向服务端发送一个查询请求,请求中包含待查询的元素。
- 布隆过滤器检查:服务端接收到查询请求后,首先将待查询的元素经过布隆过滤器中的哈希函数计算得到多个哈希值。然后,服务端对每一个哈希值进行比特位检查,判断对应的比特位是否为1。
- 判断结果:根据比特位检查的结果,服务端做出以下判断:
- 如果对于任意一个哈希值,对应的比特位为0,则可以确定待查询的元素一定不存在于集合中,直接返回查询结果,元素不存在。
- 如果对于所有哈希值,对应的比特位均为1,则说明待查询的元素可能存在于集合中,需要进一步查询底层存储系统(如数据库)来确认。
- 底层存储系统查询:如果布隆过滤器的检查结果显示元素可能存在于集合中,服务端将继续查询底层存储系统(如数据库)以确认元素是否真正存在。这一步骤可以视具体业务需求决定是否执行。
- 返回查询结果:服务端根据底层存储系统的查询结果,将最终的查询结果返回给客户端:
- 如果底层存储系统中存在该元素,则返回查询结果,元素存在于集合中。
- 如果底层存储系统中不存在该元素,则返回查询结果,元素不存在于集合中。

ps1:缓存预热是指在系统启动或者正式使用之前,提前加载一些热门或者常用的数据到缓存中,以提高系统的性能和响应速度。预热过程可以直接从数据库读取数据,并将其缓存到缓存系统中来实现。在缓存预热的同时,预热布隆过滤器。这意味着在将数据加载到缓存中的同时,也对这些数据应用布隆过滤器的哈希函数,并将对应的比特位设置为1。因此,在正式使用之前,布隆过滤器已经包含了预先加载的数据集合,从而在后续的查询过程中,可以利用布隆过滤器先行判断一个元素是否可能存在于缓存中,以提高查询效率。
ps2:布隆过滤器通常用于静态数据集合或者不经常变化的数据集合,并且在实际应用中不会经常更新。因此,在使用布隆过滤器时,通常是在初始化时构建好布隆过滤器,然后对其进行查询操作,而不是对其进行频繁的更新操作。
方案二的优缺点:
- 优点:内存占用较少,没有多余key;
- 缺点:实现复杂,存在误判
布隆过滤器是一种空间效率高、时间效率快的数据结构,用于判断一个元素是否可能存在于一个集合中。它基于一系列哈希函数和一个比特数组(bitmap,位图)构建而成。
位图:相当于是一个以(bit)位为单位的数组,数组中每个单元只能存储二进制数0或1。
布隆过滤器的原理:
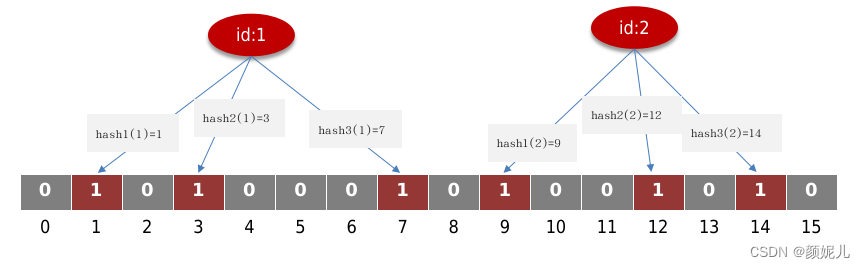
- 数据结构:布隆过滤器通常由一个长度为m的比特数组和k个不同的哈希函数构成。比特数组中的每个比特位初始都设为0。
- 添加元素:当向布隆过滤器中添加一个元素时,该元素经过k个哈希函数的计算得到k个哈希值,然后将比特数组中对应位置的比特位设为1。
- 检查元素:当需要检查一个元素是否存在于布隆过滤器中时,同样将该元素经过k个哈希函数计算得到k个哈希值,然后检查这些哈希值对应的比特位是否都为1。若存在任何一个比特位为0,则可以确定该元素一定不在布隆过滤器中;若所有的比特位均为1,则该元素可能存在于布隆过滤器中,但并不一定存在(存在一定的误判率)。
布隆过滤器的特点:
- 布隆过滤器不存储数据本身,只用于判断一个元素是否存在一个集合中。在实际应用中,布隆过滤器一旦完成初始化,通常是不会直接修改其中的数据集合的。
- 哈希冲突:布隆过滤器使用多个哈希函数将元素映射到不同的比特位上。然而,由于哈希函数的输出范围有限,不同的元素可能会映射到同一个比特位上,导致哈希冲突。当某个元素的多个哈希值对应的比特位都已经被设置为1时,其他元素经过布隆过滤器查询时可能被错误地认为存在于数据集合中,即出现误判。
- 比特位覆盖:布隆过滤器的比特数组是有限的,而待存储的元素数量是无限的。因此,布隆过滤器的比特数组大小通常是有限的,这意味着可能存在多个不同的元素映射到同一个比特位上。当一个元素被添加到布隆过滤器时,可能会覆盖掉其他元素已经占据的比特位,导致误判。
添加元素,如图:
发生检查错误的情况:
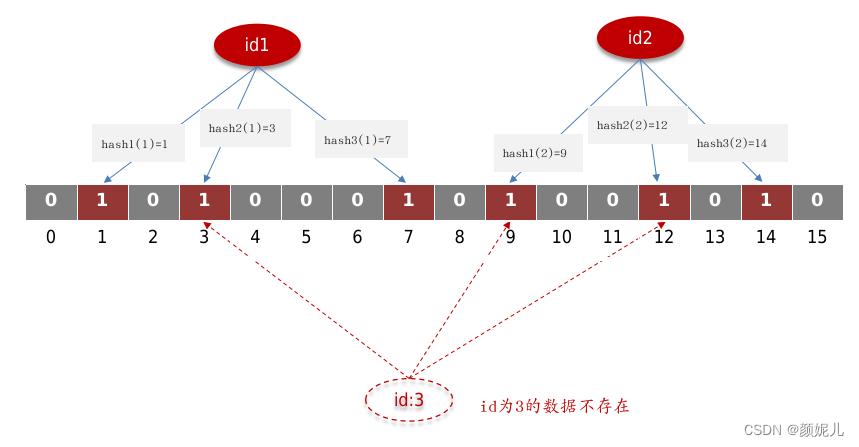
注意:在布隆过滤器中,误判是不可能避免的,一般可以通过增加布隆过滤器存储元素的个数来减少误判率。因此,在使用布隆过滤器时需要权衡误判率和内存消耗。一般,将误判率控制在5%是可以接受的。