专业的河南网站建设公司哪家好提高基层治理效能
大数据平台技术课程实验报告
实验二:HDFS操作实践
姓名:杨馥瑞
学号:2212080042
专业:数据科学与大数据技术
年级:2022级
主讲教师:林英豪
实验时间:2024年3月15日3点 至 2024年3月15日4点40
实验内容与要求:
1 HDFS基本知识总结
2 HDFS接口的操作实践
2.1 HDFS Shell 实践
2.2 HDFS Web客户端
2.3 HDFS Java API 实践
特别提醒:
(1)基本知识点的总结请使用自己的语言,根据自己的理解去总结,就像写课程笔记一样,不要去网上抄写
(2)实践需要有截图以及相应的文字介绍,欢迎大家把自己在实践过程中碰到的问题以及解决方法也记录下来
- HDFS基本知识的总结
HDFS是一个分布式文件系统,是Hadoop的核心组件之一。HDFS的设计目标是处理大数据集,能够提供高可靠性、高可扩展性和高效性的数据存储服务。下面是HDFS的一些基本知识点总结:
块:HDFS将文件划分为多个块,每个块默认大小为128MB,块的大小可以自定义设置。块的大小是为了提高数据读取的效率,减少寻址时间。
副本:HDFS会自动将文件块的副本分布到不同的数据节点上,以提高数据的可靠性和容错性。每个块的默认副本数为3,可以通过配置文件进行修改。副本分布的策略是将副本分配到不同的机架上,从而避免机架之间的单点故障。
Namenode:Namenode是HDFS的主节点,负责管理整个文件系统的命名空间、块的元数据信息和访问控制等。Namenode保存着每个文件的块列表和块所在的数据节点信息,以及每个块的副本分布情况。
Datanode:Datanode是HDFS的工作节点,负责存储文件块的实际数据。Datanode会向Namenode发送心跳信号和块状态报告,以告知Namenode自己的存储情况。如果某个块的所有副本都失效了,Namenode会通知Datanode进行块的复制。
客户端:客户端是HDFS文件系统的用户,可以使用HDFS的API进行文件的读写和管理操作。客户端首先要向Namenode发起请求,获取文件的元数据信息,然后根据元数据信息访问数据节点进行文件的读写。
数据流:HDFS将文件块的传输分成若干个数据包,每个数据包通过TCP协议进行传输。数据包的大小默认为64KB,可以通过配置文件进行修改。在数据传输过程中,每个数据包会被多个Datanode进行转发和接收,从而实现数据的并行传输。
故障恢复:HDFS采用了多种机制来保证数据的可靠性和容错性。例如,当某个块的副本失效时,Namenode会通知Datanode进行块的复制;当Namenode出现故障时,可以通过备份Namenode进行自动故障转移;当Datanode出现故障时,数据块会被复制到其他Datanode上,保证数据的可靠性。
2. HDFS的操作实践
2.1 HDFS Shell 实践
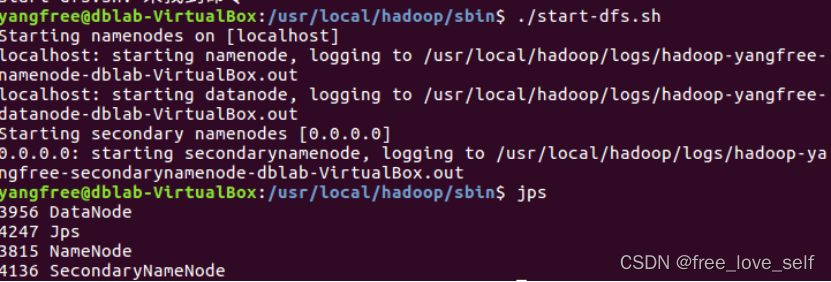
启动服务
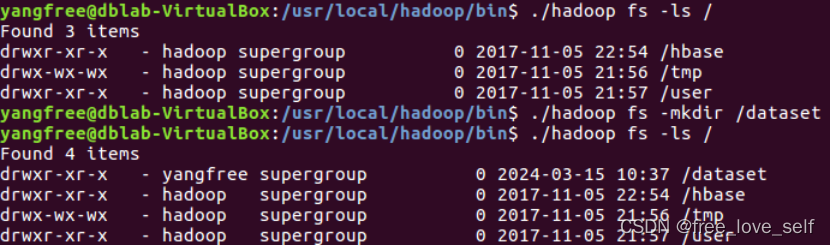
列举一个目录的路径
上传

下载

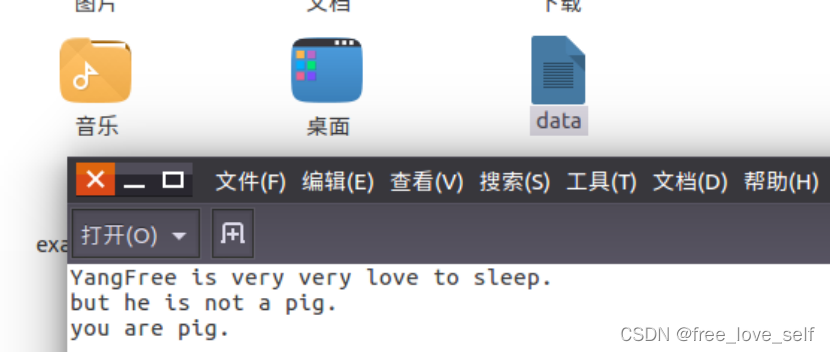
查看文件内容

删除

2.2 HDFS Web客户端
Hadoop也提供了 Web 方式来查看 HDFS 的情况。在浏览器的地址栏中输人链接 http://[NameNodeIP]:50070,便会弹出下图所示的页面。该页面显示了当前集群中 HDFS 使用的大小、活跃的节点、数据块的个数等信息。Overview 中的“localhost: 9000”显示的是HDFS的路径。该路径在后面通过Java API来访问 HDFS 时会用到。如果是单机伪分布式安装,那么NameNodeIP就是localhost。
下图所示的内容即为在伪分布式安装环境下输人 http://localhost;50070所显示的结果。通过输入该链接来查看 HDFS 的情况也常用来检验 Hadoop 集群是否安装和启动成功。

2.3HDFS Java API 实践
在实际的 Hadoop 应用过程中,最常用的是通过 Java API 的方式来访问和操作HDFS。Hadoop 主要是通过 Java 语言编写的,因此上述访问 HDFS 的FS Shell 本质上也是通过JavAPI来实现的。
下面给出基于 Java API访问 HDFS 的示例代码,以说明如何通过 Java API来实现建立目录、上传及下载文件、删除文件等主要操作。该示例代码主要通过 Maven 来实现,使用和依赖的jar 包显示在 Maven 的 pom.xml文件的 dependencies 项中。完整的 pom.xml文件显示如下:
在 pom.xml文件中配置好 jar 包依赖信息之后,还需要在 Hadoop 安装文件“/etc/hadoop”路径下的 hdfs-site.xml 文件添加配置信息,然后重启 HDFS。相关操作如下图所示:

根据课本提示,在Maven项目中建立一个名为HDFSSapp的Java类,尝试通过Java API来实现针对HDFS的目录创建、文件创建、上传及下载文件、删除文件等操作。课本示例代码已输入,部分代码如下所示:

- 问题及解决方案
出现import时部分包错误
解决方案:缺少相关文件,重新下载即可。如下图所示:

如果在下载时打断则要:彻底删除本地仓库下的全部文件,重启IEDA并reimport进行自动下载