常州商城网站制作公司制作网站模板

一、说明
BERT,或来自变形金刚(Transformer)的双向编码器表示,是由谷歌开发的强大语言模型。它已广泛用于自然语言处理任务,例如情感分析、文本分类和命名实体识别。BERT的主要特征之一是它能够生成单词嵌入,这些嵌入是单词的数字表示,捕获其含义和与其他单词的关系。
二、基础概念
词嵌入是捕获其语义含义的词的向量表示。它们用于自然语言处理任务,将单词表示为可以输入机器学习算法的数值。BERT通过考虑单词出现的上下文来生成单词嵌入,使其嵌入比传统方法(如词袋或TF-IDF)更准确和有用。
三、使用 BERT 生成词嵌入的方法
有几种方法可以使用BERT生成单词嵌入,包括:
3.1 方法 1:使用转换器库
使用BERT生成单词嵌入的最简单方法之一是通过拥抱面部使用转换器库。该库提供了一个易于使用的界面,用于处理BERT和其他变压器模型。
以下是使用此方法生成单词嵌入的步骤:
1. 安装必要的库:要使用 BERT 生成词嵌入,您需要安装“转换器”库。
!pip install transformers2. 加载 BERT 模型:安装必要的库后,您可以使用“转换器”库加载预先训练的 BERT 模型。BERT有多种版本可用,因此请选择最适合您需求的版本。
from transformers import BertModel, BertTokenizertext = "This is an example sentence."
tokens = tokenizer.tokenize(text)
print(tokens)
3. 标记化文本:在生成单词嵌入之前,您需要使用 BERT 标记器将文本标记为单个单词或子单词。这会将您的文本转换为可以输入BERT模型的格式。
text = "This is an example sentence."
tokens = tokenizer.tokenize(text)
print(tokens)['this', 'is', 'an', 'example', 'sentence', '.']4. 将令牌转换为输入 ID:将文本标记化后,您需要将标记转换为输入 ID,输入 ID 是可以输入到 BERT 模型中的标记的数字表示。
input_ids = tokenizer.convert_tokens_to_ids(tokens)
print(input_ids)[2023, 2003, 2019, 2742, 6251, 1012]5. 生成词嵌入:最后,您可以通过将输入 ID 输入到 BERT 模型中来为每个令牌生成词嵌入。该模型将返回一个张量,其中包含文本中每个标记的嵌入。
import torchinput_ids = torch.tensor(input_ids).unsqueeze(0)
with torch.no_grad():outputs = model(input_ids)embeddings = outputs.last_hidden_state[0]print(embeddings)
3.2 方法2:使用TensorFlow
使用BERT生成单词嵌入的另一种方法是使用TensorFlow,一种流行的机器学习框架。与使用转换器库相比,此方法需要更多的设置,但使您可以更好地控制该过程。
以下是使用此方法生成单词嵌入的步骤:
1. 安装必要的库:要使用 BERT 和 TensorFlow 生成词嵌入,您需要安装 TensorFlow 和 TensorFlow Hub。
!pip install tensorflow tensorflow_hub2. 加载 BERT 模型:安装必要的库后,您可以从 TensorFlow Hub 加载预先训练的 BERT 模型。
import tensorflow as tf
import tensorflow_hub as hubbert_layer = hub.KerasLayer("https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/4", trainable=False)3. 标记化文本:在生成单词嵌入之前,您需要使用 TensorFlow Hub 提供的 BERT 标记器将文本标记为单个单词或子单词。
from bert.tokenization import FullTokenizervocab_file = bert_layer.resolved_object.vocab_file.asset_path.numpy()
do_lower_case = bert_layer.resolved_object.do_lower_case.numpy()
tokenizer = FullTokenizer(vocab_file, do_lower_case)
text = "This is an example sentence."
tokens = tokenizer.tokenize(text)
print(tokens)4. 将令牌转换为输入 ID:将文本标记化后,您需要将标记转换为输入 ID,输入 ID 是可以输入到 BERT 模型中的标记的数字表示。
input_ids = tokenizer.convert_tokens_to_ids(tokens)
print(input_ids)5. 生成词嵌入:最后,您可以通过将输入 ID 输入到 BERT 模型中来为每个令牌生成词嵌入。该模型将返回一个张量,其中包含文本中每个标记的嵌入。
input_ids = tf.expand_dims(input_ids, 0)
outputs = bert_layer(input_ids)
embeddings = outputs["sequence_output"][0]
print(embeddings)3.3 使用BERT进行上下文化词嵌入
下面是如何使用BERT为句子列表生成上下文化单词嵌入的示例:
1. 设置
import pandas as pd
import numpy as np
import torch接下来,我们从Hugging Face安装变压器包,这将为我们提供一个用于BERT的pytorch接口。我们之所以选择 PyTorch 接口,是因为它在高级 API(易于使用,但不能深入了解事物的工作原理)和 TensorFlow 代码(包含大量细节,但经常将我们绕开到关于 TensorFlow 的课程,而这里的目的是 BERT)之间取得了很好的平衡。
!pip install transformers下一个:
从变压器导入 BertModel, BertTokenizer
model = BertModel.from_pretrained('bert-base-uncased',output_hidden_states = True,
)tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')

四. 创建上下文嵌入
我们必须将输入文本放入BERT可以读取的特定格式。主要是我们将 [CLS] 添加到输入的开头,将 [SEP] 添加到输入的末尾。然后我们将标记化的 BERT 输入转换为张量格式。
def bert_text_preparation(text, tokenizer):
"""
Preprocesses text input in a way that BERT can interpret.
"""
marked_text = "[CLS] " + text + " [SEP]"
tokenized_text = tokenizer.tokenize(marked_text)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
segments_ids = [1]*len(indexed_tokens)
# convert inputs to tensors
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensor = torch.tensor([segments_ids])
return tokenized_text, tokens_tensor, segments_tensor为了获得实际的BERT嵌入,我们采用预处理的输入文本,现在由张量表示,并将其放入我们预先训练的BERT模型中。
哪个向量最适合作为上下文嵌入?这取决于任务。提出BERT的原始论文研究了六个选择。我们选择了在他们的实验中效果很好的选择之一,即模型最后四层的总和。
def get_bert_embeddings(tokens_tensor, segments_tensor, model):
"""
Obtains BERT embeddings for tokens, in context of the given sentence.
"""
# gradient calculation id disabled
with torch.no_grad():
# obtain hidden states
outputs = model(tokens_tensor, segments_tensor)
hidden_states = outputs[2]
# concatenate the tensors for all layers
# use "stack" to create new dimension in tensor
token_embeddings = torch.stack(hidden_states, dim=0)
# remove dimension 1, the "batches"
token_embeddings = torch.squeeze(token_embeddings, dim=1)
# swap dimensions 0 and 1 so we can loop over tokens
token_embeddings = token_embeddings.permute(1,0,2)
# intialized list to store embeddings
token_vecs_sum = []
# "token_embeddings" is a [Y x 12 x 768] tensor
# where Y is the number of tokens in the sentence
# loop over tokens in sentence
for token in token_embeddings:
# "token" is a [12 x 768] tensor
# sum the vectors from the last four layers
sum_vec = torch.sum(token[-4:], dim=0)
token_vecs_sum.append(sum_vec)
return token_vecs_sum现在,我们可以为一组上下文创建上下文嵌入。
sentences = ["bank","he eventually sold the shares back to the bank at a premium.","the bank strongly resisted cutting interest rates.","the bank will supply and buy back foreign currency.","the bank is pressing us for repayment of the loan.","the bank left its lending rates unchanged.","the river flowed over the bank.","tall, luxuriant plants grew along the river bank.","his soldiers were arrayed along the river bank.","wild flowers adorned the river bank.","two fox cubs romped playfully on the river bank.","the jewels were kept in a bank vault.","you can stow your jewellery away in the bank.","most of the money was in storage in bank vaults.","the diamonds are shut away in a bank vault somewhere.","thieves broke into the bank vault.","can I bank on your support?","you can bank on him to hand you a reasonable bill for your services.","don't bank on your friends to help you out of trouble.","you can bank on me when you need money.","i bank on your help."]from collections import OrderedDictcontext_embeddings = []
context_tokens = []
for sentence in sentences:tokenized_text, tokens_tensor, segments_tensors = bert_text_preparation(sentence, tokenizer)list_token_embeddings = get_bert_embeddings(tokens_tensor, segments_tensors, model)# make ordered dictionary to keep track of the position of each wordtokens = OrderedDict()# loop over tokens in sensitive sentencefor token in tokenized_text[1:-1]:# keep track of position of word and whether it occurs multiple timesif token in tokens:tokens[token] += 1else:tokens[token] = 1# compute the position of the current tokentoken_indices = [i for i, t in enumerate(tokenized_text) if t == token]current_index = token_indices[tokens[token]-1]# get the corresponding embeddingtoken_vec = list_token_embeddings[current_index]# save valuescontext_tokens.append(token)context_embeddings.append(token_vec)五、比较结果
现在我们有了单词“record”的上下文嵌入,我们可以计算它与其多义兄弟和静态嵌入的相似度。
from scipy.spatial.distance import cosine# embeddings for the word 'record'
token = 'bank'
indices = [i for i, t in enumerate(context_tokens) if t == token]
token_embeddings = [context_embeddings[i] for i in indices]
# compare 'record' with different contexts
list_of_distances = []
for sentence_1, embed1 in zip(sentences, token_embeddings):for sentence_2, embed2 in zip(sentences, token_embeddings):cos_dist = 1 - cosine(embed1, embed2)list_of_distances.append([sentence_1, sentence_2, cos_dist])
distances_df = pd.DataFrame(list_of_distances, columns=['sentence_1', 'sentence_2', 'distance'])distances_df[distances_df.sentence_1 == "bank"]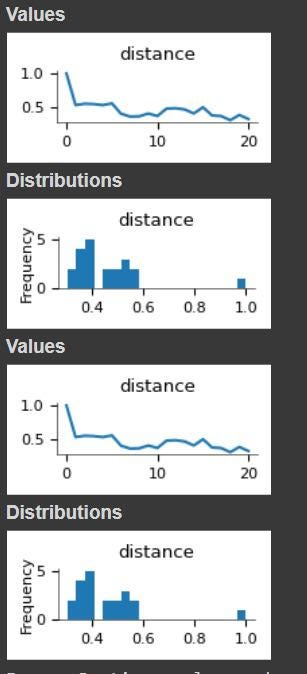
distances_df[distances_df.sentence_1 == "he eventually sold the shares back to the bank at a premium."]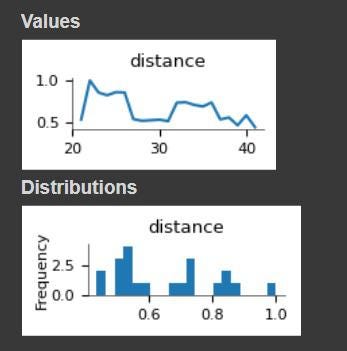
5.1 优势
上下文化嵌入:BERT生成的词嵌入考虑了词出现的上下文,使其嵌入比传统方法(如词袋或TF-IDF)更准确和有用。
迁移学习: BERT是一个预先训练的模型,可以针对特定的自然语言处理任务进行微调,使您能够利用从大量文本数据中学到的知识来提高模型的性能。
最先进的性能:BERT在广泛的自然语言处理任务上实现了最先进的性能,使其成为生成高质量单词嵌入的强大工具。
5.2 弊
计算成本: BERT是一个庞大而复杂的模型,需要大量的计算资源来生成词嵌入,因此不太适合在低功耗设备或实时应用中使用。
有限的可解释性:BERT生成的词嵌入是高维向量,可能难以解释和理解,因此很难解释使用这些嵌入的模型的行为。
5.3 差异化因素
与其他生成词嵌入的方法相比,BERT的主要区别在于它能够生成考虑到单词出现的上下文的上下文化嵌入。这使得BERT能够捕获其他方法可能遗漏的含义和用法的细微差异。
5.4 未来范围
自然语言处理领域正在迅速发展,新技术和模型一直在开发。未来的发展可能会继续提高BERT和其他模型生成的词嵌入的准确性和实用性。此外,目前正在研究如何使BERT和其他大型语言模型更加高效和可解释,这可以进一步扩展其适用性和实用性。
六、应用
BERT生成的词嵌入可用于广泛的自然语言处理任务,包括:
情绪分析:通过使用单词嵌入将文本表示为数值,可以训练机器学习算法以自动将文本的情绪分类为正面、负面或中性。
文本分类:单词嵌入可用于将文本文档表示为数值,允许机器学习算法自动将它们分类为不同的类别或主题。
命名实体识别:通过使用词嵌入来表示文本,可以训练机器学习算法以自动识别和提取命名实体,例如人员、组织和位置。
七、结论
使用BERT生成单词嵌入是将单词表示为数值的有效方法,这些数值捕获其含义和与其他单词的关系。有几种方法可以使用BERT生成单词嵌入,包括使用转换器库或TensorFlow。按照上述步骤操作,您可以轻松地为文本数据生成单词嵌入,并在自然语言处理任务中使用它们。