做网上兼职的网站公关公司经营范围
【图解大数据技术】Hadoop、HDFS、MapReduce、Yarn
- Hadoop
- HDFS
- HDFS架构
- 写文件流程
- 读文件流程
- MapReduce
- MapReduce简介
- MapReduce整体流程
- Yarn
Hadoop
Hadoop是Apache开源的分布式大数据存储与计算框架,由HDFS、MapReduce、Yarn三部分组成。广义上的Hadoop其实是指Hadoop生态圈,包括的组件就不只是HDFS、MapReduce、Yarn,还包括Spark、Flink、Zookeeper、Sqoop、Hive、HBase等工具,但是我们讨论的不是Hadoop生态圈。
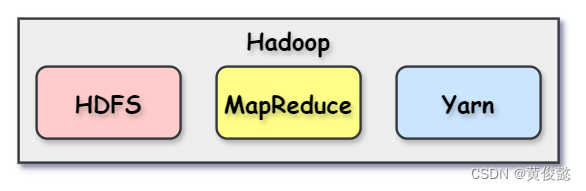
由于要解决大数据量的存储和计算问题,因此数据不能再存储在关系型数据库,而是存储在分布式文件系统HDFS中;然后通过分布式离线计算框架MapReduce进行计算;而Yarn则是负责资源调度,也就是决定计算任务调度到哪些节点上执行。
HDFS
HDFS是一个分布式文件系统,用于存储海量的文件数据。其优点是可以存储达PB级别的文件数据,百万级别以上的文件数量;而缺点则是不适合低延时数据访问,并且不支持文件修改,只支持追加。
HDFS架构
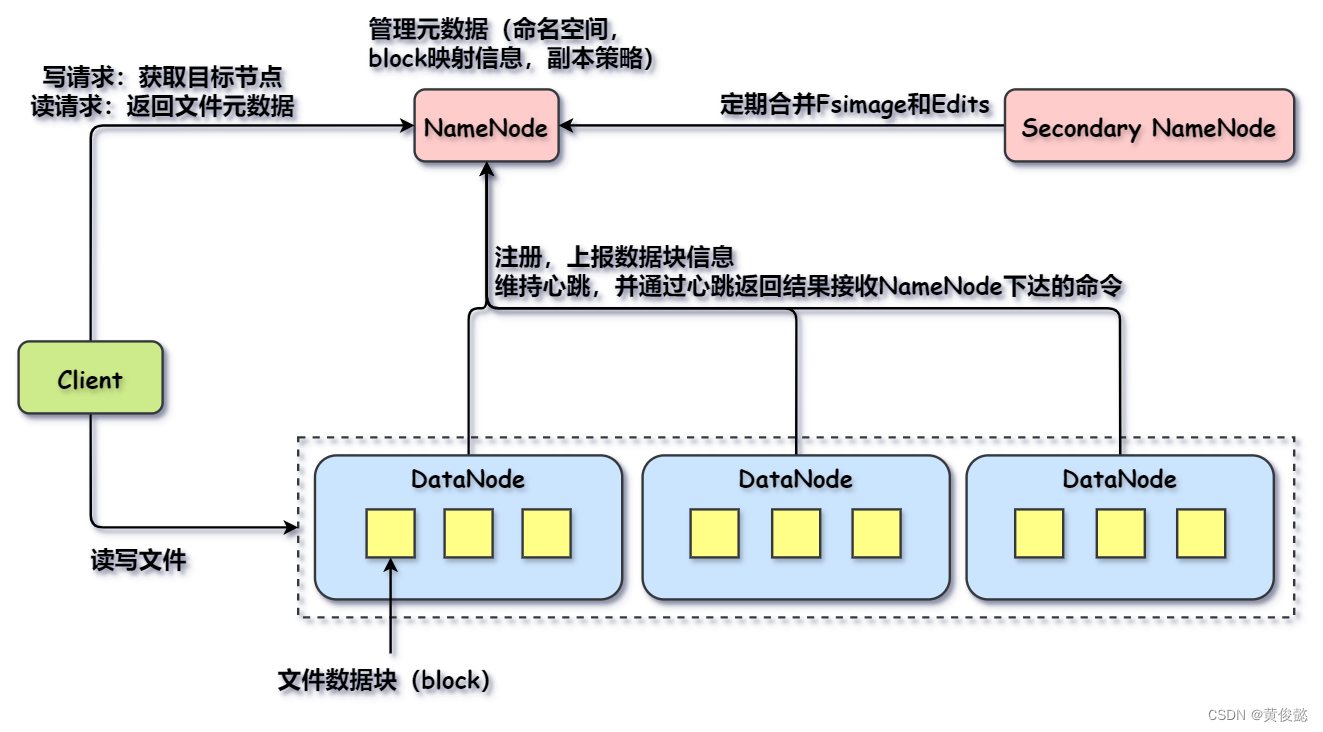
HDFS一共由四部分组成:Client、NameNode、DataNode、SecondaryNameNode。
- Client:负责文件上传之前的文件切分,切分好后传输每一个文件数据块到DataNode,上传数据块前询问NameNode该数据块上传的目标DataNode;从HDFS读取文件前询问NameNode返回文件元数据信息,再根据元数据从DataNode读取每个数据块。
- NameNode:接受DataNode的注册,存储文件的元数据信息,配置副本策略等。
- DataNode:存储文件数据块。
- SecondaryNameNode:给NameNode进行FsImage(磁盘中的元数据)和Edits(内存中的元数据,还未写入FsImage,在Edits中进行追加写记录日志)的合并。
写文件流程
文件写入流程如下:
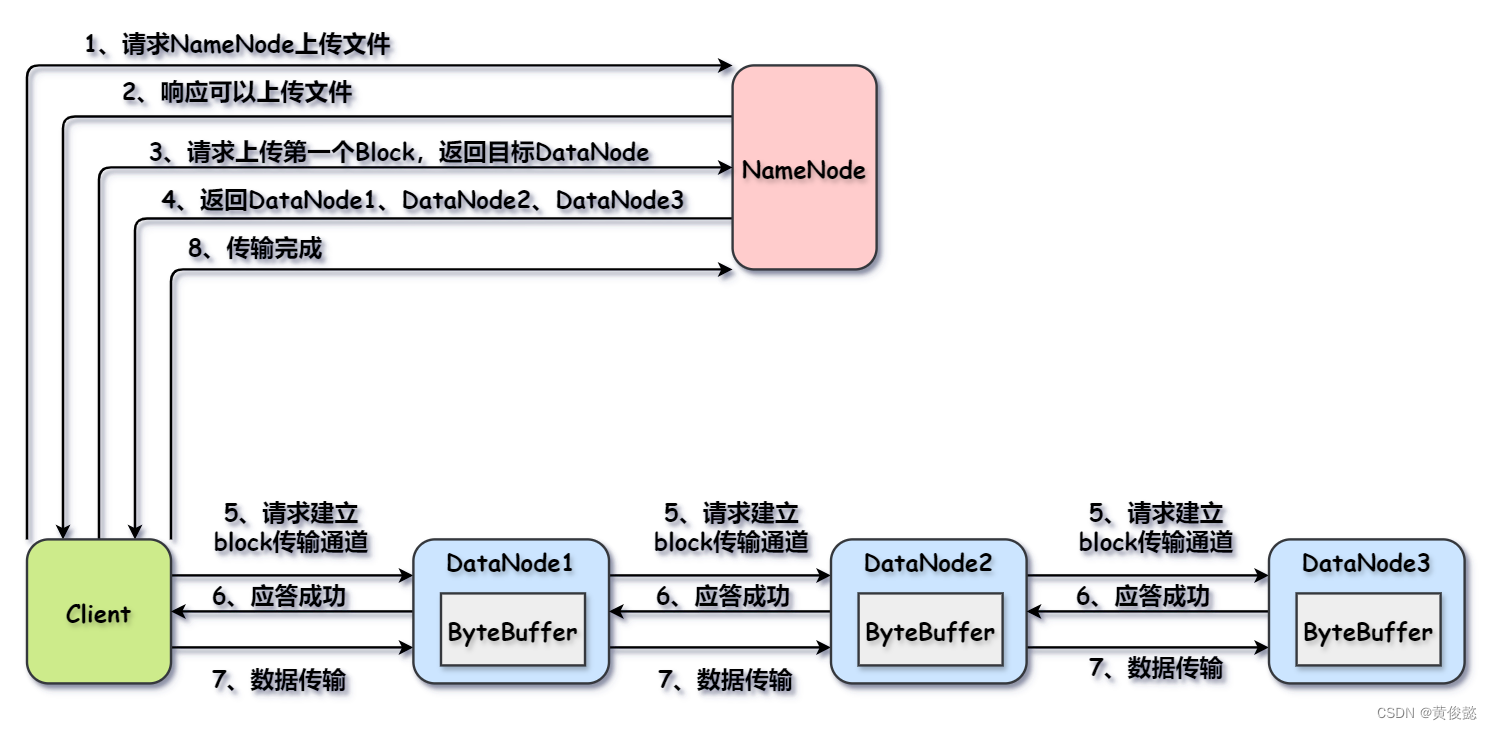
客户端在上传文件时会进行文件切割,把文件切割成一个一个的数据块block,然后分别上传每个数据块;上传每个数据块时,询问NameNode得知该数据块传输到哪些DataNode上;然后根据NameNode返回结果,上传数据块到DataNode。
读文件流程
文件读取流程如下:
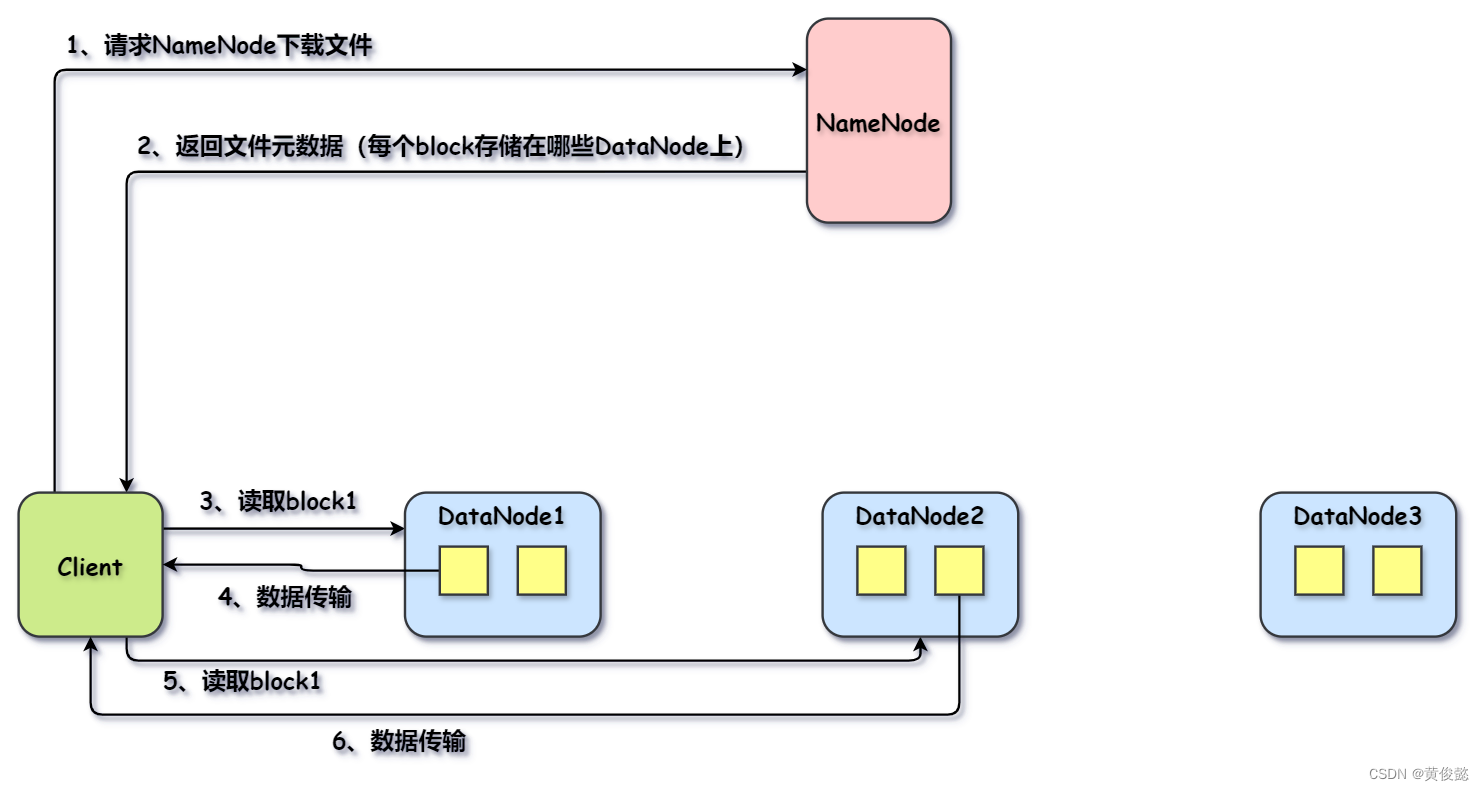
NameNode记录了文件元数据信息,比如哪个block存储在哪些DataNode。Client读取文件时,请求NameNode获取元数据信息,就可以根据元数据信息请求对应的DataNode读取对应的每个block。
MapReduce
MapReduce简介
MapReduce是一个分布式离线计算框架,专门用于处理大数据场景中与实时性无关的一些离线计算任务。
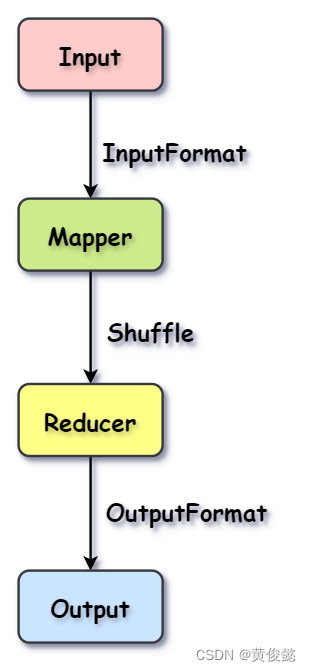
MapReduce的数据输入一般是HDFS,然后经过InputFormat进行输入格式化,变成<K,V>格式;然后执行用户实现的Mapper类型的map方法,进行数据映射,映射处理的结果也是<K,V>格式;然后执行一个shuffle过程,对映射结果进行按key进行分组分区,把同一区域的所有KV发送到同一个Reducer,由一个节点进行;Reducer对同一个key分组下的所有value进行聚合操作;然后Reducer的输出结果再经过OutputFormat进行格式化处理后进行结果输出。
MapReduce整体流程
下面是MapReduce运行的整体流程:
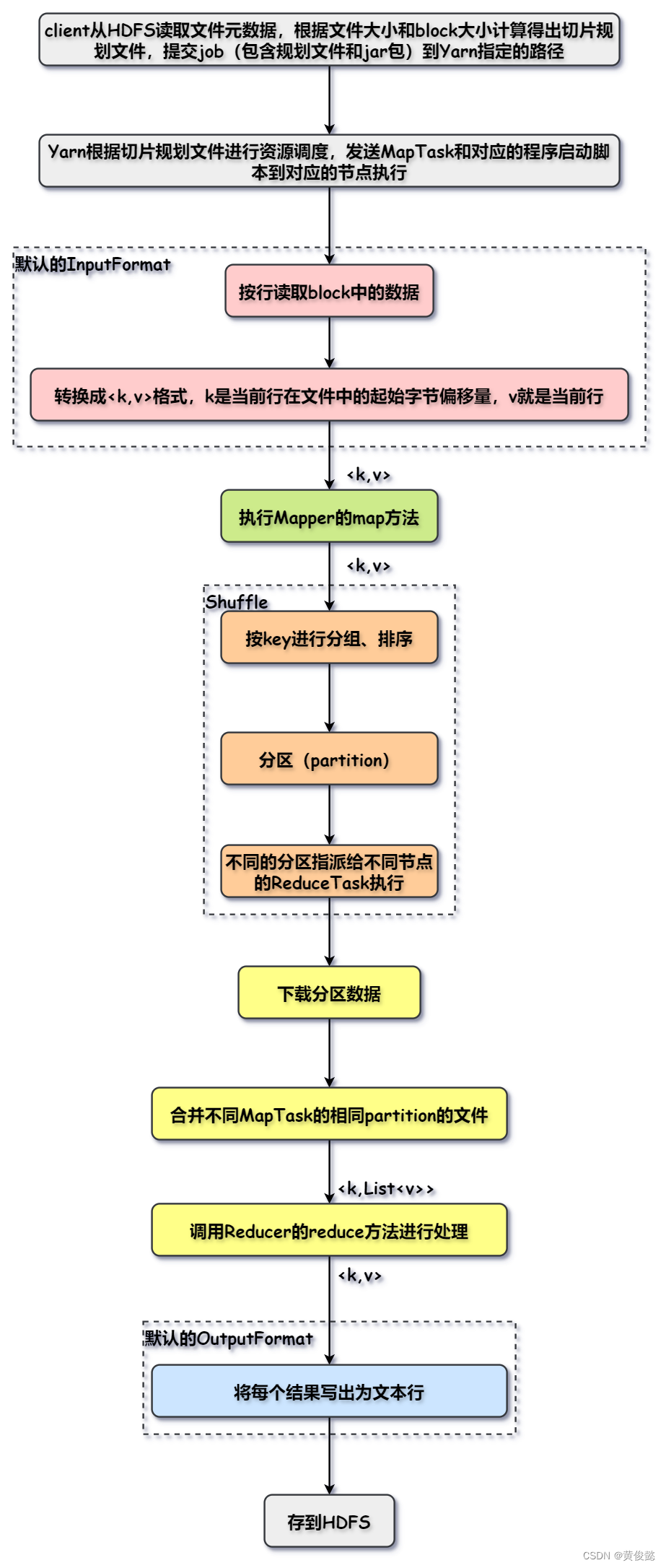
- client从HDFS读取指定文件的元数据,然后根据文件大小和block大小计算切片信息,得出切片规划文件,然后提交job到Yarn指定的路径,job中包括切片规划文件和jar包等,这个jar包包含了用户编写的Mapper和Reducer。
- Yarn根据切片数量计算MapTask的数据量,一般一个block对应一个MapTask,然后把对应的task和程序启动脚本分派给block所在的节点上运行。
- 每个节点执行对应的MapTask,默认的InputFormat读取每一行数据,然后以该行数据在文件中的起始字节偏移量为key,行数据本身作为value,调用Mapper的map方法。
- Mapper的map方法进行数据映射处理,那是用户自己实现的逻辑。
- 对计算结果进行Shuffle处理,根据key进行分组排序,然后对所有的key进行分区处理,同一分区的所有key会指派给一个ReduceTask执行,每个ReduceTask又会分派给一个节点执行。
- 执行ReduceTask的节点下载分区数据,然后对不同MapTask得出的同一partition进行合并并排序。
- 调用Reducer的reduce方法进行相应的聚合计算,这里也是由用户自己实现。
- OutputFormation把Reducer产生的结果做格式化处理,默认会写为行数据。
- 最后把结果存入HDFS中。
Yarn
Yarn是负责资源调度的,由Yarn管理每个Node节点然后进行任务分派,也就是把MapTask和ReduceTask分配给对应的Node。
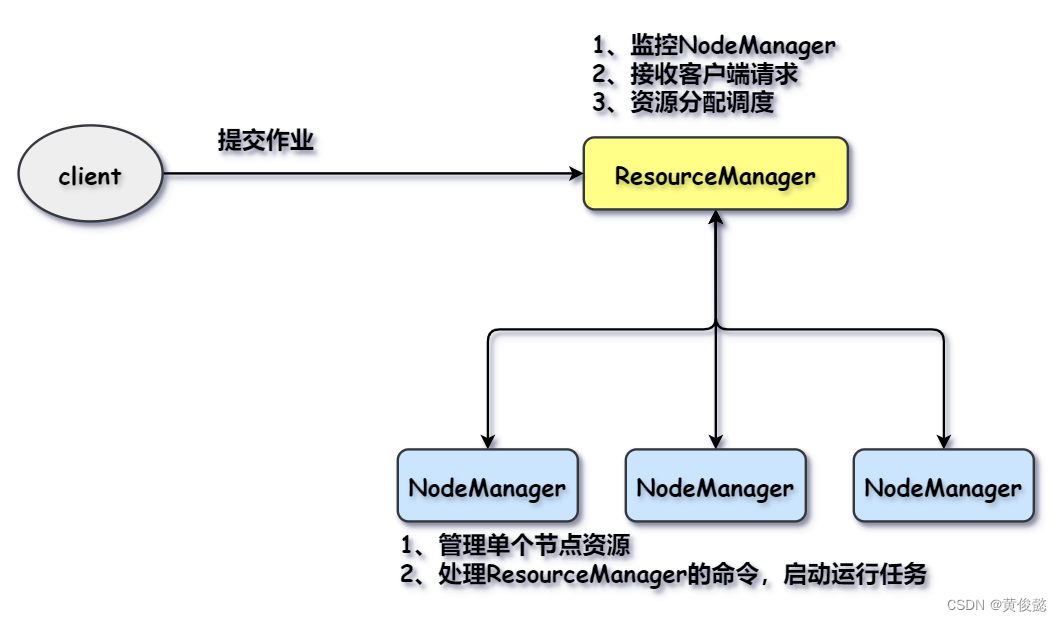
yarn有ResourceManager和NodeManager两角色。ResourceManager负责监控NodeManager,接收客户端提交的job,然后进行资源分配调度;NodeManager负责管理单个节点上的资源,并执行ResourceManager的命令,启动并运行相应的MapTask和ReduceTask。
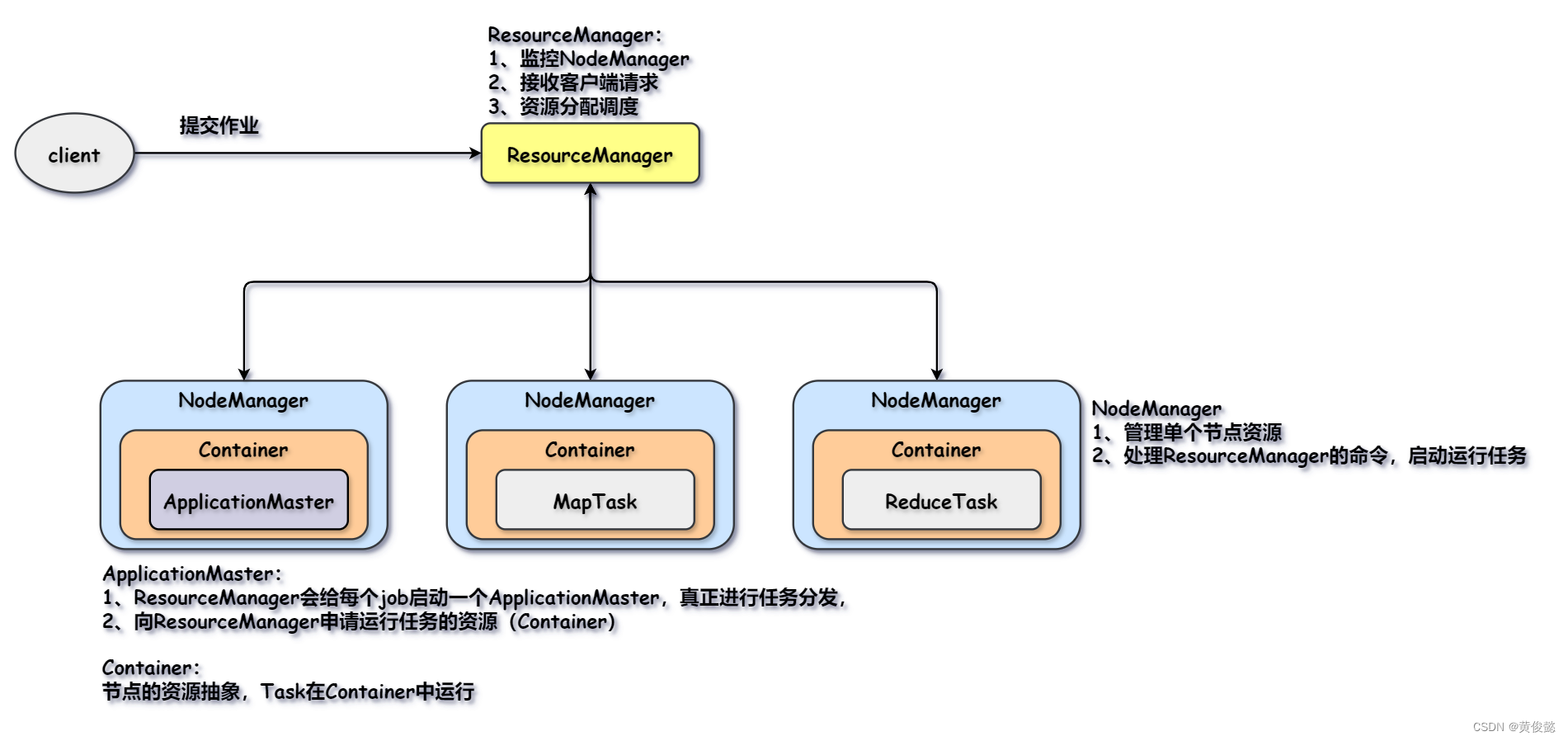
然而真正进行任务分配的并不是ResourceManager,ResourceManager每接收一个job,会选一个NodeManager来启动一个ApplicationMaster,由ApplicationMaster向ResourceManager申请资源并发送任务和启动脚本到对应的NodeManager。
而task都是在Container中运行,Container是节点资源的抽象(比如cpu、内存等),也就是限制了该task只能使用这么多资源,避免一个task占满整个node的所有资源。