一、在爬虫中,爬取的数据类型如下
1.document:返回的是一个HTML文档
2.png:无损的图片,jpg:压缩后的图片,wbep:有损压缩,比png差,比jpg好
3.avg+xml图像编码字符串
4.script:脚本文件,依据一定格式编写的可执行的文件
5.gif:图像交换格式
6.xhr:返回的是json数据类型,在没有刷新整个网页的情况下,更新部分网页,也称Ajax请求
7.包后缀是css意味着其是css样式
二、
1.几个快捷进入开发者工具的指令:
打开开发者工具方法:F12(键盘)/fn+f12/ctrl+shift+i
2.列表转字符串方法:
str.join(列表)
如'\n'.join(selector.css('.noveContent p ::text').getall())
3.files = os.listdir(filename) # 获取文件夹下所有的小视频
with zipfile.ZipFile(filename+title+'.mp4',mode='w') as z:
z.write(content)
4.print(response.text)后,在下方,按住ctrl+f键可以搜索如下图

点击:
点击.*可以用正则表达式,如果用正则表达解析数据,可以在这里尝试,可以看见匹配的数量,然后再写入代码中。
5.列表中嵌套元祖,如何快速找出元祖中的元素。
如:a=[(1,'as'),(2,'ajsh'),(781,'ajhsasa')]

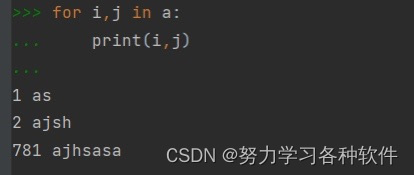
用第二张图的方法,可以直接取出元素
6.遇到参数很多,加冒号很麻烦怎么办,如下图:
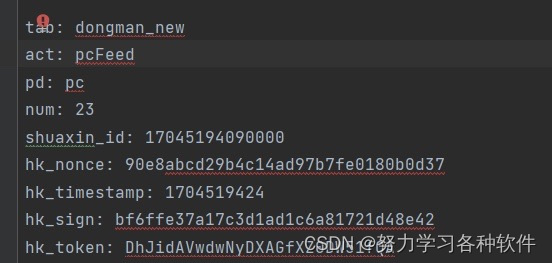
首先选中代码,按ctrl+r出现下图:
点击·*进入正则,写入下图:
代码是: (.*?): (.*)
'$1': '$2',
点击replaceall
结果展现: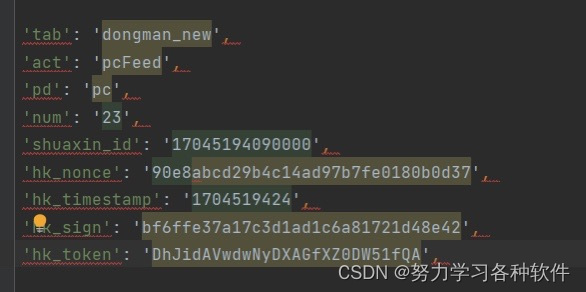
二、视频类爬虫总结
爬取短视频类型的数据一般步骤:
1.点击media,刷新,播放一个视频,会刷新一个包,点击发现是播放视频的包,
2.复制这个包url中的关键字,在搜索框中进行搜索,看有哪些包有关键字。
3.搜索后找到有play_url的包
4.看这个包的url,观察有什么规律
5.以糖豆视频为例,发现这个包的url有参数vid
6.查找参数在哪个位置
7.在xhr 动态加载中找到包,发现其中json数据中有vid的数据。
8.访问xhr 中的包获取vid数据,利用获取到的vid数据拼凑含有play_url的包的链接,访问这个链接,获取play_url
9.多页爬取,观察xhr 包的链接有什么规律,发现参数为页数,即可多页爬取
注意:访问视频play_url时,爬取短视频类型,headers中把user-agent,cookie,refer全部加上
爬取长视频的一般步骤:长视频通常以m3u8的格式存在,找包的过程与上述一致,找的是ts格式的文件,但一般存在于xhr下面。小技巧,若通过参数找不到就直接搜索m3u8,说不定可以找到终极目标是找到一个包能返回下面的界面
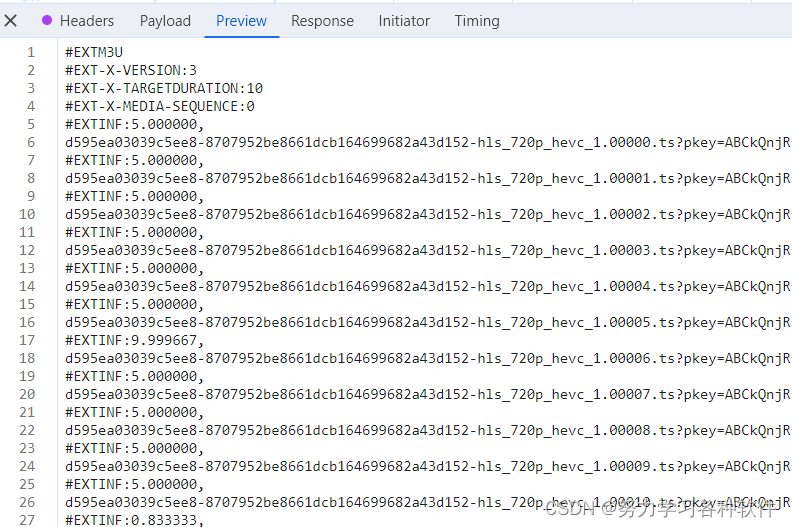
不同的网站,这个包找的地方不同,A站中搜索就可以找到,腾讯视频则先要找到一个含m3u8的包,从里面提取出一个链接,再访问这个链接,得到上面的界面。
下载时,要下载为ts的视频格式,多的一步是将文件合成。
可以将多个ts包合成一个下载代码:
with open('斗罗大陆.mp4',mode='ab') as f:f.write(ts_content)
三、打包exe与制表库的使用
1.制表模块使用prettytable
from prettytable import PrettyTable
tb = PrettyTable() # 实例化一个对象
tb.field_names = ['序号','歌手','歌名'] # 设置字段名
tb.add_row([num,singer,song_name]) # 写入表格行
2. 将python文件打包成exe文件
首先,在项目中下载pyinstaller包pip install pyinstaller
然后在需要打包的python文件目录路径下输入cmd

在终端输入:pyinstaller -F 文件名.py
成功后会出现dit的文件夹,里面有exe的文件