奉贤宜昌网站建设搜狗网站排名软件
从注意力机制(attention)开始,近两年提及最多的就是Transformer了,那么Transformer到底是什么机制,凭啥这么牛?各个领域都能用?一文带你揭开Transformer的神秘面纱。
目录
1.深度学习(DL)背景介绍
2.Transformer的发展历程
3.Transformer优缺点
3.1Transformer的优点
3.2Transformer的缺点
4.Transformer详细过程
4.1Transformer为什么可以并行?
4.2归纳偏置
4.3特征提取能力与自编码器
1.深度学习(DL)背景介绍
深度学习自出生以来就不被看好,随着计算机的发展和硬件条件的提升,这种大规模计算的深度学习才重新焕发光芒。但是我们都知道深度学习,甚至是深度强化学习的效率太慢了,人类只需要重复学习几次,甚至几十次就可以学会的东西,深度学习需要成千上万次,不得不感叹深度学习算法的学习真的太慢了。
深度学习的学习效率问题是由于其本身算法计算机制导致的,最初的深度学习算法都是靠梯度下降来完成映射的,在学习过程中,为了避免学了新的,忘记旧的的“猴子掰玉米”式的学习方式,算法不得不在训练过程中,让每个增量都很小,然后不断重复这个过程,如此一来,就导致学习过程非常缓慢。
2.Transformer的发展历程
2016——CNN中引入Attention机制解决CNN模型结构只能提取local信息缺乏考虑全局信息能力的问题
2017 ——论文《Attentnion is all you need》提出的 seq2seq 模型
2021——ViT的出现使用完全的Transformer模型替代CNN,解决图像领域问题
2023——直今,开始研究对CV Transformer细节的优化,包括对于高分辨率图像如何提升运行效率、如何更好的将图像转换成序列以保持图像的结构信息、如何进行运行效率和效果的平衡等
3.Transformer优缺点
3.1Transformer的优点
- 可并行
- 弱归纳偏置,通用性强
- 特征抽取能力强
- 自编码上下文双向建模
3.2Transformer的缺点
-
self-attention 计算复杂度高,序列长度上升,复杂度指数级上升
-
弱归纳偏置增加了小数据集上过拟合的风险
4.Transformer详细过程
4.1Transformer为什么可以并行?
NLP中的RNN之所以不能并行化,是因为其是一个马尔可夫过程,即当前状态只与前一个状态有关,而与再之前的所有状态无关。它天生是个时序结构,t时刻依赖t-1时刻的输出,而t-1时刻又依赖t-2时刻,如此循环往前,我们可以说t时刻依赖了前t时刻所有的信息。
Transformer可以并行化的重要部分体现在两个方面:Encoder和Decoder。Transformer的核心之一是self-Attention自注意力机制,其中,自注意力机制就是利用两个输入之间两两相关性作为权重的一种加权平均,将每一个输入映射到输出上。所以从这个层面上来说,Transformer的Encoder部分里,输出与之前所有的输入都有关,并不是只依赖上一个输入,因此,Transformer的Encoder可以并行化计算所有的自注意力机制。
Transformer的Decoder部分,引入了一种“teacher force”的概念,就是每个时刻的输入不依赖上一时刻的输出,而是依赖之前所有正确的样本,而正确的样本在训练集中已经全部提供了。正是这种“teacher force”的思想,才可以在Transformer的Decoder部分进行并行化计算,
值得注意的一点是:Decoder的并行化仅在训练阶段,在测试阶段,因为我们没有label,所以t时刻的输入必然依赖t-1时刻的输出,这时跟之前的NLP中的序列预测就没什么区别了。
4.2归纳偏置
归纳偏置(In Terms of Inductive Bias)其实可以理解为:从现实生活中观察到的现象中归纳出一定的规则,然后对模型做一定的约束,从而可以起到“模型选择”的作用,即从假设空间中选择出更符合现实规则的模型,也可以理解为“先验知识”。打个比方,第一次用智能手机的人类,可能从前还用过其他的设备。那里的经验,就可以帮他很快学会智能手机的用法。如果没有那些经验,就只能广泛尝试,影响学习速度了。回到AI上来,用过去的经验来加速学习,在机器学习里叫做元学习 (Meta-Learning) 。
Transformer很少对数据的结构信息进行假设。这使得Transformer成为一个通用且灵活的体系结构。但是这样也有其对应的缺点。缺少结构归纳偏置使得Transformer容易对小规模数据过拟合。
归纳 (Induction) 是自然科学中常用的两大方法之一 (归纳与演绎,Induction & Deduction),指从一些例子中寻找共性、泛化,形成一个较通用的规则的过程。偏置 (Bias) 则是指对模型的偏好。通俗理解:归纳偏置可以理解为,从现实生活中观察到的现象中归纳出一定的规则 (heuristics),然后对模型做一定的约束,从而可以起到 “模型选择” 的作用,类似贝叶斯学习中的 “先验”。
4.3特征提取能力与自编码器
Transformer强大的特征提取能力来源于自注意力机制,
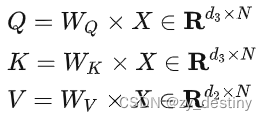
其中,Q为查询向量序列,K为键向量序列,V为值向量序列,W为可学习参数矩阵。
Transformer可以加深网络深度,不像 CNN 只能将模型添加到 2 至 3 层,这样它能够获取更多全局信息,进而提升模型准确率。
整理不易,欢迎一键三连!!!
持续更新。。。
参考:如何理解Inductive bias? - 知乎